Na początku tego miesiąca opublikowałem wskazówkę dotyczącą czegoś, czego prawdopodobnie wszyscy nie chcielibyśmy robić:sortować lub usuwać duplikaty z rozdzielanych ciągów, zazwyczaj obejmujące funkcje zdefiniowane przez użytkownika (UDF). Czasami trzeba ponownie złożyć listę (bez duplikatów) w kolejności alfabetycznej, a czasami może być konieczne zachowanie oryginalnej kolejności (może to być na przykład lista kluczowych kolumn w złym indeksie).
W moim rozwiązaniu, które dotyczy obu scenariuszy, użyłem tabeli liczb wraz z parą funkcji zdefiniowanych przez użytkownika (UDF) – jedną do dzielenia łańcucha, a drugą do jego ponownego złożenia. Możesz zobaczyć tę wskazówkę tutaj:
- Usuwanie duplikatów z ciągów w SQL Server
Oczywiście istnieje wiele sposobów rozwiązania tego problemu; Podałem tylko jedną metodę do wypróbowania, jeśli utkniesz z danymi struktury. Red-Gate @Phil_Factor opublikował krótki post pokazujący jego podejście, w którym unika się funkcji i tabeli liczb, a zamiast tego decyduje się na manipulację w formacie XML. Mówi, że woli mieć zapytania składające się z pojedynczych instrukcji i unikać zarówno funkcji, jak i przetwarzania wiersz po wierszu:
- Deduplikacja rozdzielonych list w SQL Server
Następnie czytelnik, Steve Mangiameli, opublikował zapętlone rozwiązanie jako komentarz pod wskazówką. Jego rozumowanie było takie, że użycie tabeli liczb wydawało mu się przesadne.
Wszystkim nam trzem nie udało się rozwiązać tego aspektu, który zwykle jest dość ważny, jeśli wykonujesz zadanie wystarczająco często lub na dowolnym poziomie skali:wydajność .
Testowanie
Zaciekawiony, jak dobrze sprawdziłyby się wbudowane metody XML i pętle w porównaniu z moim rozwiązaniem opartym na tabeli liczb, zbudowałem fikcyjną tabelę, aby wykonać kilka testów; moim celem było 5000 wierszy, ze średnią długością ciągu większą niż 250 znaków i co najmniej 10 elementami w każdym ciągu. Dzięki bardzo krótkiemu cyklowi eksperymentów udało mi się osiągnąć coś bardzo zbliżonego do tego za pomocą następującego kodu:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Spowodowało to powstanie tabeli z przykładowymi wierszami wyglądającymi tak (wartości obcięte):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Dane jako całość miały następujący profil, który powinien być wystarczająco dobry, aby wykryć potencjalne problemy z wydajnością:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Zauważ, że przełączyłem się na varchar tutaj z nvarchar w oryginalnym artykule, ponieważ próbki dostarczone przez Phila i Steve'a zakładały varchar , ciągi kończące się tylko na 255 lub 8000 znaków, ograniczniki jednoznakowe itp. Nauczyłem się swojej lekcji na własnej skórze, że jeśli zamierzasz wziąć czyjąś funkcję i uwzględnić ją w porównaniach wydajności, zmienisz tylko możliwe – najlepiej nic. W rzeczywistości zawsze używałbym nvarchar i nie zakładaj niczego o najdłuższym możliwym ciągu. W tym przypadku wiedziałem, że nie stracę żadnych danych, ponieważ najdłuższy ciąg ma tylko 2905 znaków, a w tej bazie danych nie mam żadnych tabel ani kolumn, które używają znaków Unicode.
Następnie stworzyłem swoje funkcje (które wymagają tabeli liczb). Czytelnik zauważył błąd w funkcji w mojej wskazówce, w którym założyłem, że ogranicznik zawsze będzie pojedynczym znakiem, i poprawił to tutaj. Przekonwertowałem też prawie wszystko na varchar(8000) aby wyrównać szanse pod względem rodzajów i długości strun.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Następnie utworzyłem pojedynczą, wbudowaną funkcję z wartościami tabelarycznymi, która połączyła dwie powyższe funkcje, co teraz chciałbym zrobić w oryginalnym artykule, aby całkowicie uniknąć funkcji skalarnej. (Chociaż to prawda, że nie wszystkie funkcje skalarne są okropne na dużą skalę, jest bardzo niewiele wyjątków).
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Utworzyłem również oddzielne wersje wbudowanego TVF, które były dedykowane do każdego z dwóch wyborów sortowania, aby uniknąć zmienności CASE ekspresji, ale okazało się, że nie ma to żadnego dramatycznego wpływu.
Następnie stworzyłem dwie funkcje Steve'a:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Następnie umieściłem bezpośrednie zapytania Phila na moim stanowisku testowym (zauważ, że jego zapytania kodują < jako < aby chronić je przed błędami parsowania XML, ale nie kodują > lub & – Dodałem symbole zastępcze na wypadek, gdyby trzeba było chronić się przed ciągami, które potencjalnie mogą zawierać te problematyczne znaki):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Tester składał się w zasadzie z tych dwóch zapytań, a także z następujących wywołań funkcji. Po sprawdzeniu, że wszystkie zwracają te same dane, przeplatałem skrypt z DATEDIFF wypisz i zarejestrował to w tabeli:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Następnie przeprowadziłem testy wydajności na dwóch różnych systemach (jeden czterordzeniowy z 8 GB i jeden 8-rdzeniowy VM z 32 GB), i w każdym przypadku zarówno na SQL Server 2012, jak i SQL Server 2016 CTP 3.2 (13.0.900.73).
Wyniki
Zaobserwowane przeze mnie wyniki podsumowano na poniższym wykresie, który pokazuje czas trwania każdego typu zapytania w milisekundach, uśredniony w kolejności alfabetycznej i oryginalnej, cztery kombinacje serwer/wersja oraz serię 15 wykonań dla każdej permutacji. Kliknij, aby powiększyć:
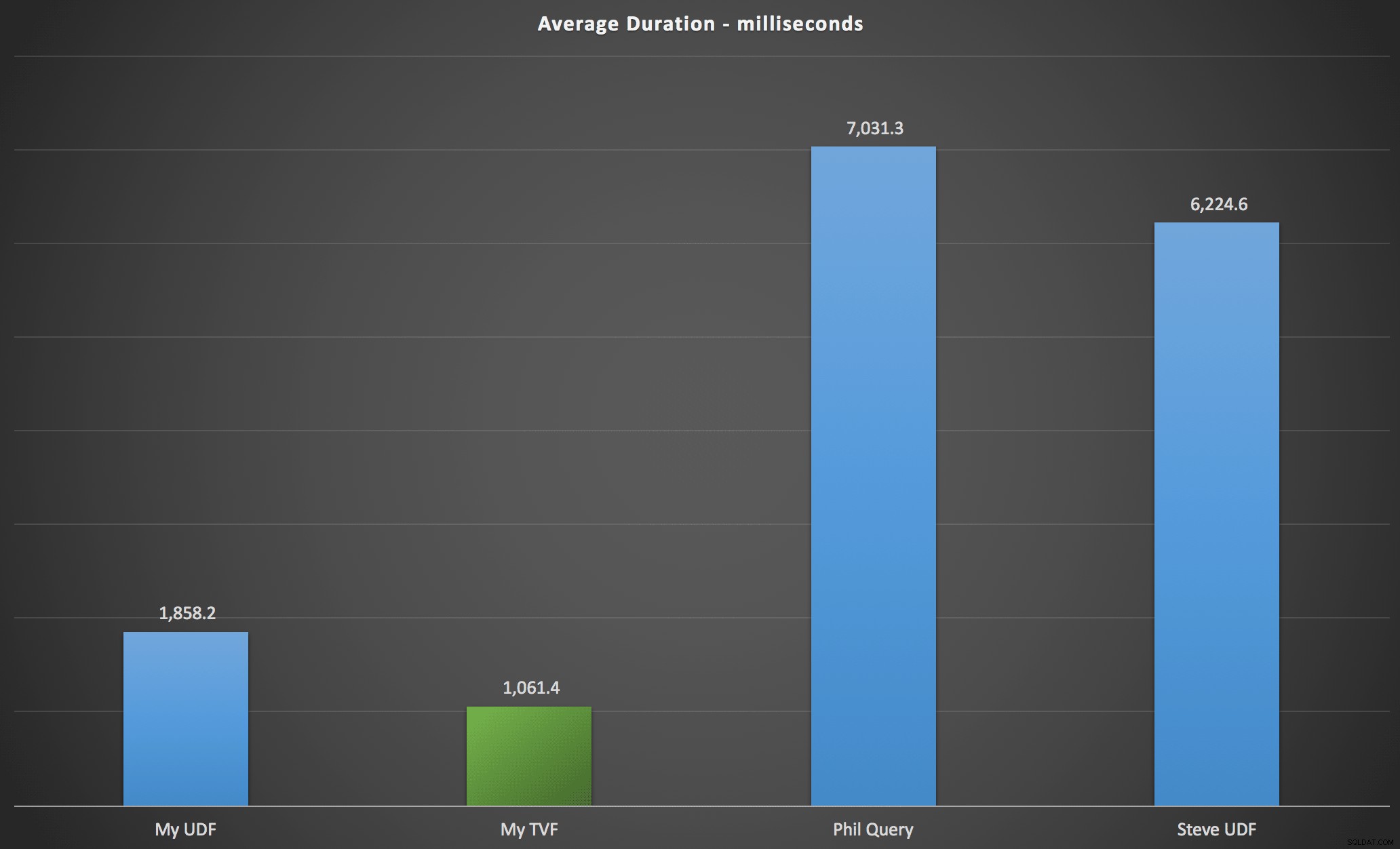
To pokazuje, że tabela liczb, choć uważana za przeprojektowaną, w rzeczywistości przyniosła najbardziej wydajne rozwiązanie (przynajmniej pod względem czasu trwania). Oczywiście było to lepsze z pojedynczym TVF, który zaimplementowałem niedawno, niż z zagnieżdżonymi funkcjami z oryginalnego artykułu, ale oba rozwiązania krążą wokół dwóch alternatyw.
Aby uzyskać bardziej szczegółowe informacje, poniżej znajdują się podziały dla każdej maszyny, wersji i typu zapytania w celu zachowania oryginalnej kolejności:
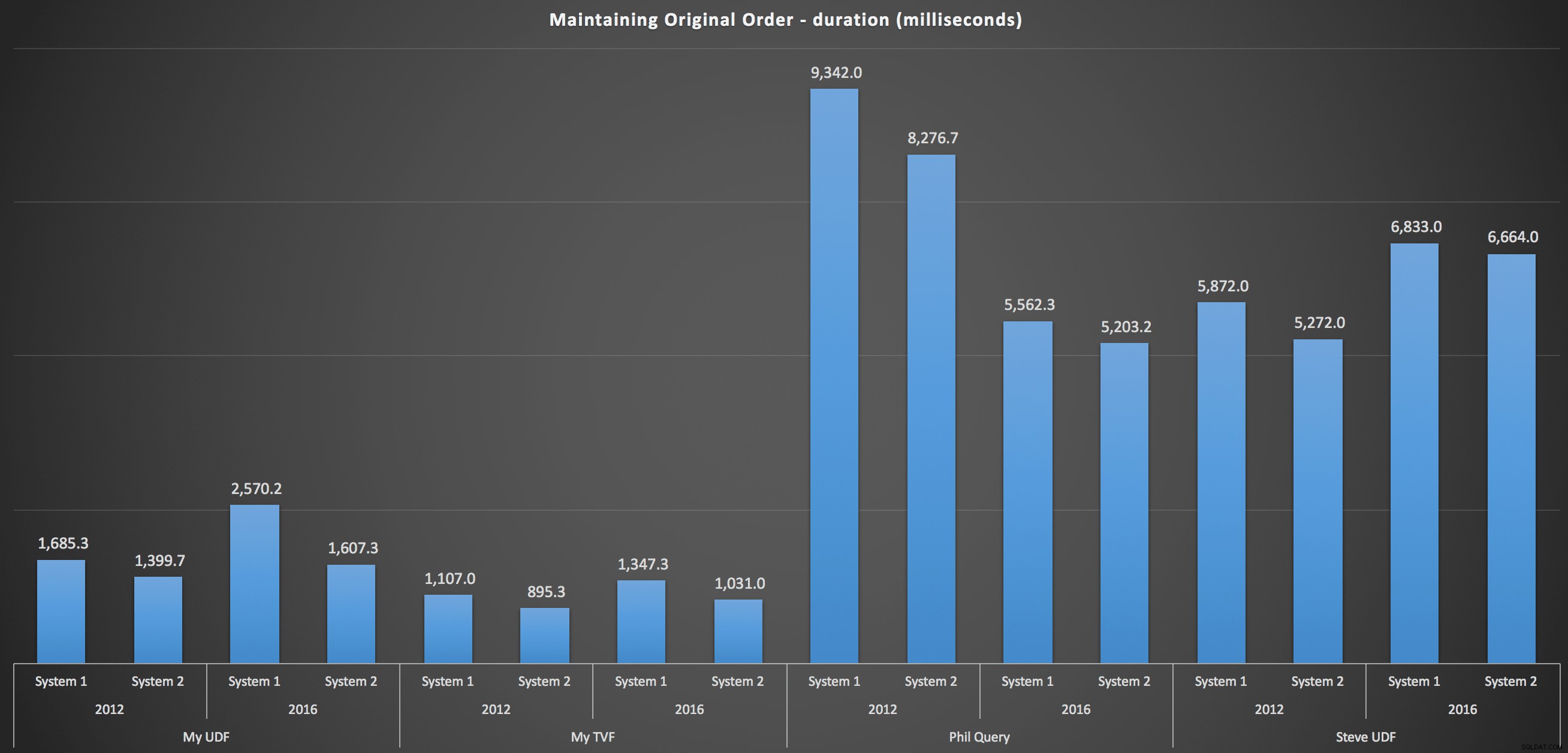
…i ponowne ułożenie listy w kolejności alfabetycznej:
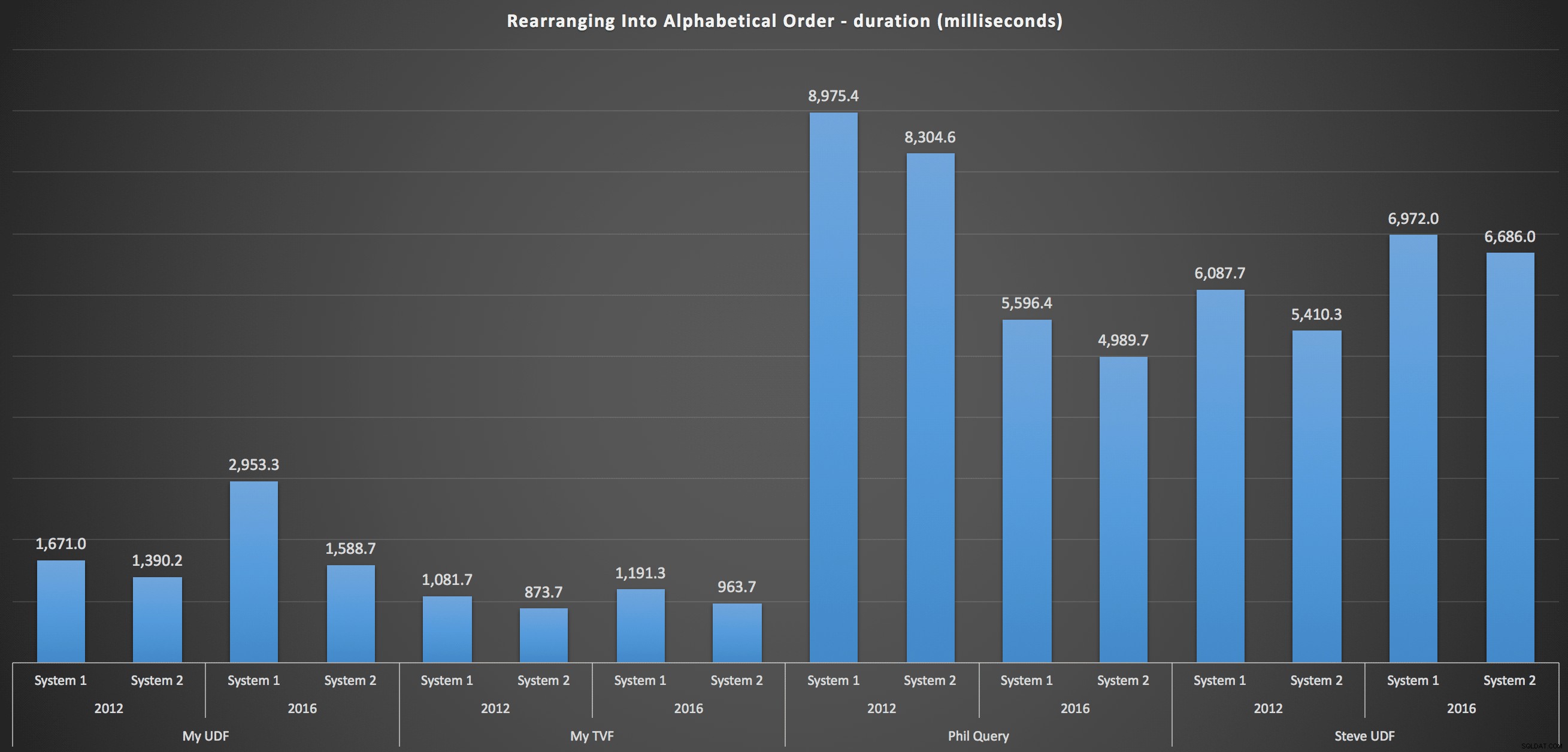
Pokazują one, że wybór sortowania miał niewielki wpływ na wynik – oba wykresy są praktycznie identyczne. Ma to sens, ponieważ biorąc pod uwagę formę danych wejściowych, nie mogę sobie wyobrazić żadnego indeksu, który sprawiłby, że sortowanie byłoby bardziej wydajne – jest to podejście iteracyjne, bez względu na to, jak je pokroisz lub jak zwrócisz dane. Ale jasne jest, że niektóre podejścia iteracyjne mogą być ogólnie gorsze od innych i niekoniecznie jest to użycie UDF (lub tabeli liczb), która sprawia, że są takie.
Wniosek
Dopóki nie będziemy dysponować natywną funkcją podziału i konkatenacji w SQL Server, będziemy używać wszelkiego rodzaju nieintuicyjnych metod, aby wykonać zadanie, w tym funkcji zdefiniowanych przez użytkownika. Jeśli obsługujesz pojedynczy ciąg na raz, nie zobaczysz dużej różnicy. Ale w miarę zwiększania się ilości danych warto poświęcić chwilę na przetestowanie różnych podejść (i wcale nie sugeruję, że powyższe metody są najlepsze, jakie znajdziesz – na przykład nawet nie spojrzałem na CLR lub inne podejścia T-SQL z tej serii).