Każdy programista powie Ci, że pisanie bezpiecznego kodu wielowątkowego może być trudne. Wymaga dużej staranności i dobrego zrozumienia związanych z tym kwestii technicznych. Jako osoba zajmująca się bazą danych możesz pomyśleć, że tego rodzaju trudności i komplikacje nie dotyczą pisania T-SQL. Dlatego trochę szokujące może być uświadomienie sobie, że kod T-SQL jest również podatny na wyścigi i inne zagrożenia integralności danych, najczęściej kojarzone z programowaniem wielowątkowym. Dzieje się tak niezależnie od tego, czy mówimy o pojedynczej instrukcji T-SQL, czy o grupie instrukcji zawartych w jawnej transakcji.
Sednem problemu jest fakt, że systemy bazodanowe umożliwiają wykonywanie wielu transakcji jednocześnie. Jest to dobrze znany (i bardzo pożądany) stan rzeczy, jednak w dużej części produkcyjnego kodu T-SQL nadal po cichu zakłada się, że dane bazowe nie zmieniają się podczas wykonywania transakcji lub pojedynczej instrukcji DML, takiej jak SELECT , INSERT , UPDATE , DELETE lub MERGE .
Nawet jeśli autor kodu jest świadomy możliwych skutków równoczesnych zmian danych, zbyt często zakłada się, że użycie jawnych transakcji zapewnia większą ochronę niż jest to faktycznie uzasadnione. Te założenia i nieporozumienia mogą być subtelne i z pewnością mogą wprowadzić w błąd nawet doświadczonych praktyków baz danych.
Teraz zdarzają się przypadki, w których kwestie te nie będą miały większego znaczenia w sensie praktycznym. Na przykład baza danych może być tylko do odczytu lub może istnieć jakaś inna prawdziwa gwarancja że nikt inny nie zmieni podstawowych danych, gdy z nimi pracujemy. Podobnie, operacja, o której mowa, nie może wymagać wyniki, które są dokładnie prawidłowy; nasi konsumenci danych mogą być całkowicie zadowoleni z przybliżonego wyniku (nawet takiego, który nie odzwierciedla stanu bazy danych w dowolnym punkt w czasie).
Problemy ze współbieżnością
Kwestia interferencji między współbieżnie wykonywanymi zadaniami jest znanym problemem dla twórców aplikacji pracujących w językach programowania, takich jak C# czy Java. Rozwiązania są liczne i zróżnicowane, ale generalnie wymagają użycia operacji atomowych lub uzyskanie wzajemnie wykluczającego się zasobu (takiego jak blokada ), gdy trwa wrażliwa operacja. Jeśli nie zostaną podjęte odpowiednie środki ostrożności, prawdopodobnymi rezultatami są uszkodzone dane, błąd, a może nawet całkowita awaria.
Wiele z tych samych pojęć (np. operacje atomowe i blokady) istnieje w świecie baz danych, ale niestety często mają one kluczowe różnice w znaczeniu . Większość osób zajmujących się bazami danych jest świadoma właściwości ACID transakcji bazodanowych, gdzie A oznacza atomowy . SQL Server używa również blokad (i innych wewnętrznych urządzeń wykluczających). Żaden z tych terminów nie oznacza dokładnie tego, czego rozsądnie oczekiwałby doświadczony programista C# lub Java, a wielu specjalistów od baz danych również ma niejasne rozumienie tych tematów (o czym świadczy szybkie wyszukiwanie za pomocą ulubionej wyszukiwarki).
Przypomnijmy, że czasami kwestie te nie będą stanowić praktycznego problemu. Jeśli piszesz zapytanie, aby zliczyć liczbę aktywnych zamówień w systemie bazy danych, jak ważne jest to, że liczba ta jest nieco przesunięta? A może odzwierciedla stan bazy danych w innym momencie?
Rzeczywiste systemy często dokonują kompromisu między współbieżnością a spójnością (nawet jeśli projektant nie był tego świadomy w tym czasie – poinformowany kompromisy są prawdopodobnie rzadszym zwierzęciem). Prawdziwe systemy często działają wystarczająco , z wszelkimi anomaliami krótkotrwałymi lub uznanymi za nieistotne. Użytkownik widząc niespójny stan na stronie internetowej często rozwiązuje problem, odświeżając stronę. Jeśli problem zostanie zgłoszony, najprawdopodobniej zostanie zamknięty jako Nie do odtworzenia. Nie mówię, że jest to pożądany stan rzeczy, po prostu uznaję, że tak się dzieje.
Niemniej jednak niezwykle przydatne jest zrozumienie zagadnień współbieżności na podstawowym poziomie. Świadomość ich pozwala nam pisać poprawnie (lub poinformowana wystarczająco poprawne) T-SQL, zgodnie z wymaganiami. Co ważniejsze, pozwala nam to uniknąć pisania T-SQL, które mogłoby zagrozić logicznej integralności naszych danych.
Ale SQL Server zapewnia gwarancje ACID!
Tak, ale nie zawsze są takie, jakich można by się spodziewać i nie chronią wszystkiego. Najczęściej ludzie czytają znacznie więcej w ACID niż jest to uzasadnione.
Najczęściej błędnie rozumianymi składnikami akronimu ACID są słowa Atomic, Consistent i Isolated – do nich przejdziemy za chwilę. Drugi, Trwałe , jest wystarczająco intuicyjne, o ile pamiętasz, że dotyczy tylko trwałych (możliwy do odzyskania) użytkownik dane.
Biorąc to wszystko pod uwagę, SQL Server 2014 zaczyna nieco zacierać granice właściwości Durable, wprowadzając ogólną opóźnioną trwałość i trwałość tylko w schemacie OLTP w pamięci. Wspominam o nich tylko dla kompletności, nie będziemy dalej omawiać tych nowych funkcji. Przejdźmy do bardziej problematycznych właściwości ACID:
Własność atomowa
Wiele języków programowania zapewnia operacje atomowe które mogą być używane do ochrony przed wyścigami i innymi niepożądanymi efektami współbieżności, w których wiele wątków wykonania może uzyskiwać dostęp lub modyfikować współużytkowane struktury danych. Dla dewelopera aplikacji operacja atomowa ma wyraźną gwarancję całkowitej izolacji z efektów innego współbieżnego przetwarzania w programie wielowątkowym.
Analogiczna sytuacja ma miejsce w świecie baz danych, gdzie wiele zapytań T-SQL jednocześnie uzyskuje dostęp i modyfikuje współdzielone dane (tj. bazę danych) z różnych wątków. Zauważ, że nie mówimy tutaj o zapytaniach równoległych; zwykłe zapytania jednowątkowe są rutynowo zaplanowane do równoczesnego uruchamiania w SQL Server w oddzielnych wątkach roboczych.
Niestety, właściwość atomowa transakcji SQL gwarantuje tylko, że modyfikacje danych wykonane w ramach transakcji powodzenie lub niepowodzenie jako jednostka . Nic więcej. Z pewnością nie ma gwarancji całkowitej izolacji od skutków innego równoczesnego przetwarzania. Zauważ też mimochodem, że właściwość transakcji atomowej nie mówi nic o jakichkolwiek gwarancjach dotyczących odczytu dane.
Pojedyncze oświadczenia
Nie ma też nic szczególnego w jednym stwierdzeniu w SQL Server. Gdzie jawna transakcja zawierająca (BEGIN TRAN...COMMIT TRAN ) nie istnieje, pojedyncza instrukcja DML jest nadal wykonywana w ramach transakcji automatycznego zatwierdzania. Te same gwarancje ACID dotyczą pojedynczego oświadczenia, a także te same ograniczenia. W szczególności pojedyncze oświadczenie nie ma żadnych specjalnych gwarancji, że dane nie ulegną zmianie w trakcie.
Rozważ następujące zapytanie w AdventureWorks:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); Zapytanie ma na celu wyświetlenie informacji o Zamówieniu, które zostało sklasyfikowane jako pierwsze według ilości. Plan wykonania jest następujący:
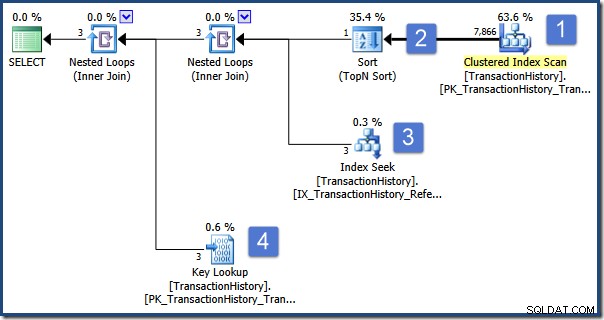
Główne operacje w tym planie to:
- Przeskanuj tabelę, aby znaleźć wiersze z wymaganym typem transakcji
- Znajdź identyfikator zamówienia, który sortuje się najwyżej zgodnie ze specyfikacją w podzapytaniu
- Znajdź wiersze (w tej samej tabeli) z wybranym identyfikatorem zamówienia za pomocą indeksu nieklastrowego
- Wyszukaj pozostałe dane kolumny za pomocą indeksu klastrowego
Teraz wyobraź sobie, że jednoczesny użytkownik modyfikuje Zamówienie 495, zmieniając jego Typ transakcji z P na W i zatwierdza tę zmianę w bazie danych. Traf chciał, że ta modyfikacja przechodzi, gdy nasze zapytanie wykonuje operację sortowania (krok 2).
Po zakończeniu sortowania indeks wyszukiwania w kroku 3 znajduje wiersze z wybranym identyfikatorem zamówienia (którym jest 495), a wyszukiwanie klucza w kroku 4 pobiera pozostałe kolumny z tabeli bazowej (gdzie typ transakcji to teraz W) .
Ta sekwencja zdarzeń oznacza, że nasze zapytanie daje pozornie niemożliwy wynik:

Zamiast wyszukiwania zleceń z typem transakcji P jako określonym zapytaniem, wyniki pokazują typ transakcji W.
Podstawowa przyczyna jest jasna:nasze zapytanie domyślnie założyło, że dane nie mogą się zmienić w trakcie wykonywania zapytania z jedną instrukcją. Okno możliwości w tym przypadku było stosunkowo duże ze względu na sortowanie blokujące, ale ogólnie rzecz biorąc, ten sam rodzaj wyścigu może wystąpić na każdym etapie wykonywania zapytania. Oczywiście ryzyko jest zwykle wyższe przy zwiększonych poziomach współbieżnych modyfikacji, większych tabelach i miejscach, w których w planie zapytania pojawiają się operatory blokujące.
Innym uporczywym mitem w tym samym obszarze ogólnym jest to, że MERGE ma być preferowane nad oddzielnym INSERT , UPDATE i DELETE instrukcji, ponieważ jednoinstrukcja MERGE jest atomowy. To oczywiście bzdura. Wrócimy do tego rodzaju rozumowania w dalszej części serii.
Ogólnym przesłaniem w tym momencie jest to, że o ile nie zostaną podjęte wyraźne kroki w celu zapewnienia inaczej, wiersze danych i wpisy indeksu mogą się zmienić, przesunąć pozycję lub całkowicie zniknąć w dowolnym momencie procesu wykonywania. Podczas pisania zapytań T-SQL warto mieć na uwadze obraz ciągłych i losowych zmian w bazie danych.
Właściwość spójności
Drugie słowo z akronimu ACID również ma szereg możliwych interpretacji. W bazie danych SQL Server spójność oznacza tylko transakcja pozostawia bazę danych w stanie, który nie narusza żadnych aktywnych ograniczeń. Ważne jest, aby w pełni docenić, jak ograniczone jest to stwierdzenie:Jedynymi gwarancjami ACID integralności danych i logicznej spójności są te, które zapewniają aktywne ograniczenia.
SQL Server zapewnia ograniczony zakres ograniczeń w celu wymuszenia spójności logicznej, w tym PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE i NOT NULL . Gwarantujemy, że wszystkie te zostaną spełnione w momencie, gdy transakcja zostanie zatwierdzona. Ponadto SQL Server gwarantuje fizyczne oczywiście integralność bazy danych przez cały czas.
Wbudowane ograniczenia nie zawsze są wystarczające do wymuszenia wszystkich oczekiwanych przez nas zasad biznesowych i integralności danych. Z pewnością można być kreatywnym ze standardowymi udogodnieniami, ale te szybko stają się skomplikowane i mogą skutkować przechowywaniem zduplikowanych danych.
W konsekwencji większość prawdziwych baz danych zawiera przynajmniej niektóre procedury T-SQL napisane w celu wymuszenia dodatkowych reguł, na przykład w procedurach składowanych i wyzwalaczach. Odpowiedzialność za zapewnienie poprawnego działania tego kodu spoczywa wyłącznie na autorze – właściwość Spójność nie zapewnia żadnych szczególnych zabezpieczeń.
Aby podkreślić tę kwestię, pseudo-ograniczenia napisane w T-SQL muszą działać poprawnie bez względu na to, jakie współbieżne modyfikacje mogą mieć miejsce. Deweloper aplikacji może chronić tak poufną operację za pomocą instrukcji lock. Najbliższą rzeczą, jaką programiści T-SQL mają do tej funkcji dla zagrożonych procedur składowanych i kodu wyzwalającego, jest stosunkowo rzadko używany sp_getapplock systemowa procedura składowana. Nie oznacza to, że jest to jedyna, a nawet preferowana opcja, po prostu istnieje i może być właściwym wyborem w niektórych okolicznościach.
Właściwość izolacji
Jest to najczęściej błędnie rozumiane właściwości transakcji ACID.
Zasadniczo całkowicie odizolowany transakcja jest wykonywana jako jedyne zadanie wykonywane na bazie danych w okresie jej istnienia. Inne transakcje można rozpocząć dopiero po całkowitym zakończeniu bieżącej transakcji (tj. zatwierdzeniu lub wycofaniu). Przeprowadzona w ten sposób transakcja byłaby naprawdę operacją atomową , w ścisłym znaczeniu, które osoba niebędąca bazą danych przypisałaby frazie.
W praktyce transakcje bazodanowe działają w stopień izolacji określony przez aktualnie obowiązujący poziom izolacji transakcji (pamiętaj, że dotyczy to również samodzielnych wyciągów). Ten kompromis (stopień izolacji) jest praktyczną konsekwencją wspomnianych wcześniej kompromisów między współbieżnością a poprawnością. System, który dosłownie przetwarzałby transakcje pojedynczo, bez nakładania się w czasie, zapewniłby całkowitą izolację, ale ogólna przepustowość systemu prawdopodobnie byłaby niska.
Następnym razem
W następnej części tej serii będziemy kontynuować badanie problemów ze współbieżnością, właściwości ACID i izolację transakcji ze szczegółowym spojrzeniem na poziom izolacji możliwy do serializacji, kolejny przykład czegoś, co może nie oznaczać tego, co Twoim zdaniem robi.
[ Zobacz indeks dla całej serii ]