Łączenie dwóch lub więcej zestawów danych jest najczęściej wyrażane w T-SQL za pomocą UNION ALL klauzula. Biorąc pod uwagę, że optymalizator SQL Server może często zmieniać kolejność takich rzeczy, jak łączenia i agregacje w celu poprawy wydajności, całkiem rozsądne jest oczekiwanie, że SQL Server rozważy również zmianę kolejności danych wejściowych konkatenacji, jeśli zapewniłoby to przewagę. Na przykład optymalizator może rozważyć korzyści z przepisania A UNION ALL B jako B UNION ALL A .
W rzeczywistości optymalizator SQL Server nie Zrób to. Dokładniej, istniała ograniczona obsługa zmiany kolejności wprowadzania konkatenacji w wersjach SQL Server do 2008 R2, ale została ona usunięta w SQL Server 2012 i od tego czasu nie pojawił się ponownie.
SQL Server 2008 R2
Intuicyjnie, kolejność konkatenacji danych wejściowych ma znaczenie tylko wtedy, gdy istnieje cel w wierszu . Domyślnie SQL Server optymalizuje plany wykonania na podstawie tego, że wszystkie kwalifikujące się wiersze zostaną zwrócone do klienta. Gdy obowiązuje cel dotyczący wiersza, optymalizator próbuje znaleźć plan wykonania, który szybko utworzy kilka pierwszych wierszy.
Cele wierszy można ustawić na wiele sposobów, na przykład za pomocą TOP , a FAST n wskazówka zapytania lub za pomocą EXISTS (który ze swej natury musi znaleźć co najwyżej jeden rząd). Tam, gdzie nie ma celu dotyczącego wiersza (tj. klient wymaga wszystkich wierszy), generalnie nie ma znaczenia, w jakiej kolejności odczytywane są dane wejściowe konkatenacji:w każdym przypadku każde dane wejściowe zostaną ostatecznie w pełni przetworzone.
Ograniczona obsługa w wersjach do SQL Server 2008 R2 ma zastosowanie tam, gdzie celem jest dokładnie jeden wiersz . W tej konkretnej sytuacji SQL Server zmieni kolejność danych wejściowych konkatenacji na podstawie oczekiwanych kosztów.
Nie jest to wykonywane podczas optymalizacji opartej na kosztach (jak można by się spodziewać), ale raczej jako przepisanie w ostatniej chwili normalnych wyników optymalizacji po optymalizacji. Ten układ ma tę zaletę, że nie zwiększa przestrzeni wyszukiwania planu w oparciu o koszty (potencjalnie jedna alternatywa dla każdej możliwej zmiany kolejności), a jednocześnie tworzy plan zoptymalizowany pod kątem szybkiego zwracania pierwszego wiersza.
Przykłady
Poniższe przykłady używają dwóch tabel o identycznej zawartości:Milion wierszy liczb całkowitych od jednego do miliona. Jedna tabela to sterta bez indeksów nieklastrowanych; drugi ma unikalny indeks klastrowy:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Brak celu w rzędzie
Poniższe zapytanie szuka tych samych wierszy w każdej tabeli i zwraca połączenie dwóch zestawów:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Plan wykonania wygenerowany przez optymalizator zapytań to:
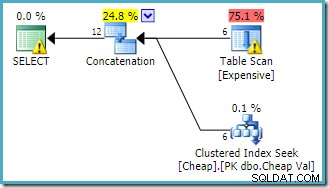
Ostrzeżenie w katalogu głównym SELECT operator ostrzega nas o oczywistym braku indeksu w tabeli sterty. Ostrzeżenie dla operatora Table Scan jest dodawane przez Sentry One Plan Explorer. Zwraca naszą uwagę na koszt I/O predykatu rezydualnego ukrytego w skanie.
Kolejność wejść do konkatenacji nie ma tutaj znaczenia, ponieważ nie wyznaczyliśmy celu wiersza. Oba dane wejściowe zostaną w pełni odczytane, aby zwrócić wszystkie wiersze wyników. Interesujące (choć nie jest to gwarantowane) zauważ, że kolejność danych wejściowych jest zgodna z kolejnością tekstową oryginalnego zapytania. Zauważ również, że kolejność wierszy wyników końcowych również nie jest określona, ponieważ nie użyliśmy najwyższego poziomu ORDER BY klauzula. Założymy, że jest to celowe, a ostateczne zamówienie jest nieistotne dla wykonywanego zadania.
Jeśli odwrócimy pisemną kolejność tabel w zapytaniu w ten sposób:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Plan wykonania podąża za zmianą, najpierw uzyskując dostęp do tabeli klastrowanej (ponownie, nie jest to gwarantowane):
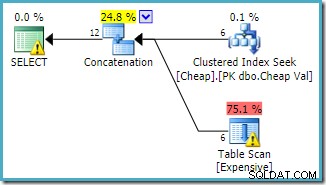
Można oczekiwać, że oba zapytania będą miały tę samą charakterystykę wydajności, ponieważ wykonują te same operacje, tylko w innej kolejności.
Z bramką w rzędzie
Oczywiście brak indeksowania w tabeli sterty zwykle powoduje, że znajdowanie określonych wierszy jest droższe w porównaniu z tą samą operacją w tabeli klastrowej. Jeśli poprosimy optymalizatora o plan, który szybko zwróci pierwszy wiersz, spodziewamy się, że SQL Server zmieni kolejność wejść konkatenacji, aby najpierw sprawdzić tanią tabelę klastrową.
Używając zapytania, które najpierw wymienia tabelę sterty, i używając podpowiedzi do zapytania FAST 1, aby określić cel wiersza:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Szacowany plan wykonania wygenerowany na wystąpieniu SQL Server 2008 R2 jest:
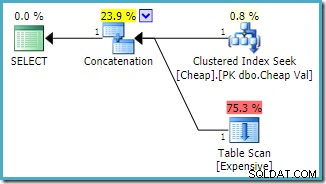
Zwróć uwagę, że dane wejściowe konkatenacji zostały uporządkowane w celu zmniejszenia szacowanego kosztu zwrócenia pierwszego wiersza. Należy również zauważyć, że brakujący indeks i pozostałe ostrzeżenia we/wy zniknęły. Żaden problem nie ma znaczenia w przypadku tego kształtu planu, gdy celem jest jak najszybsze zwrócenie pojedynczego wiersza.
To samo zapytanie wykonane na SQL Server 2016 (przy użyciu jednego z modeli szacowania kardynalności) to:
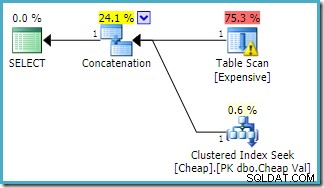
SQL Server 2016 nie zmienił kolejności wejść konkatenacji. Zwróciło ostrzeżenie we/wy eksploratora planu, ale niestety optymalizator tym razem nie wygenerował ostrzeżenia o braku indeksu (chociaż jest to istotne).
Ogólne zmiany kolejności
Jak wspomniano, przepisywanie po optymalizacji, które zmienia kolejność danych wejściowych konkatenacji, jest skuteczne tylko w przypadku:
- SQL Server 2008 R2 i wcześniejsze
- Cel rzędu dokładnie jednego
Jeśli naprawdę chcemy zwrócić tylko jeden wiersz, a nie plan zoptymalizowany do szybkiego zwrócenia pierwszego wiersza (ale który ostatecznie zwróci wszystkie wiersze), możemy użyć TOP klauzula z tabelą pochodną lub wspólnym wyrażeniem tabelowym (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
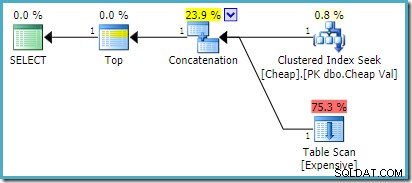
) AS UA; W SQL Server 2008 R2 lub starszym daje to optymalny plan zmiany kolejności wprowadzania danych:
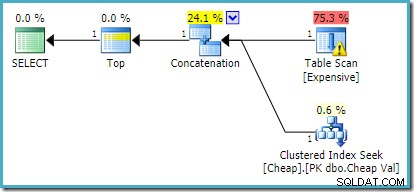
W SQL Server 2012, 2014 i 2016 nie występuje zmiana kolejności po optymalizacji:
Jeśli chcemy zwrócić więcej niż jeden wiersz, na przykład za pomocą TOP (2) , żądane przepisanie nie zostanie zastosowane na SQL Server 2008 R2, nawet jeśli FAST 1 podpowiedź jest również używana. W takiej sytuacji musimy uciec się do sztuczek, takich jak użycie TOP ze zmienną i OPTIMIZE FOR wskazówka:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint Wskazówka dotycząca zapytania wystarczy, aby ustawić cel rzędu jeden, podczas gdy wartość zmiennej w czasie wykonywania zapewnia zwrócenie żądanej liczby wierszy (2).
Rzeczywisty plan wykonania na SQL Server 2008 R2 to:
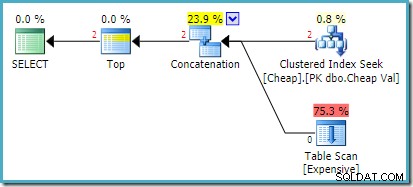
Oba zwrócone wiersze pochodzą z danych wejściowych wyszukiwania o zmienionej kolejności, a skanowanie tabeli nie jest w ogóle wykonywane. Eksplorator planów wyświetla liczbę wierszy na czerwono, ponieważ oszacowanie dotyczyło jednego wiersza (ze względu na wskazówkę), podczas gdy w czasie wykonywania napotkano dwa wiersze.
Bez UNION ALL
Ten problem nie ogranicza się również do zapytań napisanych jawnie za pomocą UNION ALL . Inne konstrukcje, takie jak EXISTS i OR może również spowodować, że optymalizator wprowadzi operator konkatenacji, który może ucierpieć z powodu braku zmiany kolejności danych wejściowych. Niedawno pojawiło się pytanie dotyczące wymiany stosów administratorów baz danych z dokładnie tym problemem. Przekształcenie zapytania z tego pytania, aby użyć naszych przykładowych tabel:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
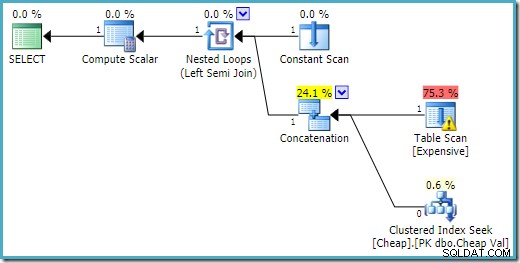
END; Plan wykonania na SQL Server 2016 zawiera tabelę sterty na pierwszym wejściu:
W SQL Server 2008 R2 kolejność danych wejściowych jest zoptymalizowana, aby odzwierciedlić jednowierszowy cel sprzężenia częściowego:
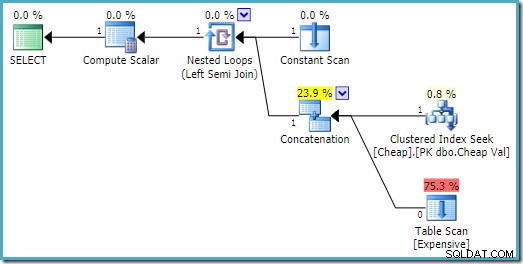
W bardziej optymalnym planie skanowanie sterty nigdy nie jest wykonywane.
Obejścia
W niektórych przypadkach dla autora zapytania będzie oczywiste, że jedno z wejść konkatenacji będzie zawsze tańsze w obsłudze niż pozostałe. Jeśli to prawda, całkiem słuszne jest przepisanie zapytania tak, aby tańsze dane wejściowe konkatenacji pojawiały się jako pierwsze w kolejności pisemnej. Oczywiście oznacza to, że autor zapytań musi być świadomy tego ograniczenia optymalizatora i przygotowany do polegania na nieudokumentowanym zachowaniu.
Trudniejsza kwestia pojawia się, gdy koszt danych wejściowych konkatenacji zmienia się w zależności od okoliczności, być może w zależności od wartości parametrów. Używanie OPTION (RECOMPILE) nie pomoże na SQL Server 2012 lub nowszym. Ta opcja może być pomocna w SQL Server 2008 R2 lub starszym, ale tylko wtedy, gdy spełniony jest również wymóg dotyczący jednego wiersza.
Jeśli istnieją obawy dotyczące polegania na obserwowanym zachowaniu (dane wejściowe konkatenacji planu zapytania pasujące do kolejności tekstowej zapytania), przewodnik planu może zostać użyty do wymuszenia kształtu planu. Tam, gdzie różne zamówienia wejściowe są optymalne dla różnych okoliczności, można zastosować wiele przewodników planu, w których warunki można dokładnie zakodować z wyprzedzeniem. Nie jest to jednak idealne.
Ostateczne myśli
Optymalizator zapytań SQL Server w rzeczywistości zawiera oparty na kosztach reguła eksploracji, UNIAReorderInputs , który jest w stanie generować konkatenacyjne warianty kolejności wprowadzania danych i badać alternatywy podczas optymalizacji opartej na kosztach (nie jako jednorazowego przepisywania po optymalizacji).
Ta reguła nie jest obecnie włączona do ogólnego użytku. O ile wiem, jest aktywowany tylko wtedy, gdy przewodnik po planie lub USE PLAN podpowiedź jest obecna. Umożliwia to silnikowi pomyślne wymuszenie planu, który został wygenerowany dla zapytania, które zakwalifikowało się do przepisania ze zmianą kolejności danych wejściowych, nawet jeśli bieżące zapytanie się nie kwalifikuje.
Mam wrażenie, że ta reguła eksploracji jest celowo ograniczona do tego zastosowania, ponieważ zapytania, które mogłyby skorzystać na ponownym uporządkowaniu danych wejściowych konkatenacji w ramach optymalizacji opartej na kosztach, nie są uważane za wystarczająco powszechne, a być może dlatego, że istnieje obawa, że dodatkowy wysiłek nie będzie opłacał się wyłączony. Moim zdaniem zmiana kolejności wprowadzania danych przez operatora konkatenacji powinna być zawsze sprawdzana, gdy obowiązuje cel dotyczący wiersza.
Szkoda również, że (bardziej ograniczone) przepisywanie po optymalizacji nie jest skuteczne w SQL Server 2012 lub nowszych. Mogło to być spowodowane subtelnym błędem, ale nie mogłem znaleźć niczego na ten temat w dokumentacji, bazie wiedzy ani na Connect. Dodałem tutaj nowy element Connect.
Aktualizacja 9 sierpnia 2017 :to jest teraz naprawione pod flagą śledzenia 4199 dla programu SQL Server 2014 i 2016, zobacz KB 4023419:
POPRAWKA:Zapytanie z UNION ALL i celem wiersza może działać wolniej w SQL Server 2014 lub nowszych wersjach w porównaniu z SQL Server 2008 R2