Ten post jest częścią serii o bramkach rzędowych. Pozostałe części znajdziesz tutaj:
- Część 1:Ustalanie i identyfikacja celów wierszy
- Część 2:Półzłącza
- Część 3:Zapobieganie łączeniom
Zastosuj blokowanie połączeń z najlepszym operatorem
Często zobaczysz wewnętrzny operator Top (1) w zastosuj anty sprzężenia plany wykonawcze. Na przykład przy użyciu bazy danych AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Plan pokazuje operator Top (1) po wewnętrznej stronie Apply (odniesienia zewnętrzne) anti join:
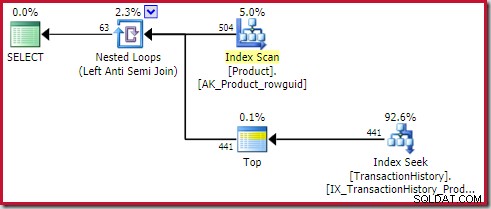
Ten najlepszy operator jest całkowicie zbędny . Nie jest to wymagane ze względu na poprawność, wydajność ani zapewnienie ustalonego celu wiersza.
Operator Apply anti join przestanie sprawdzać wiersze po wewnętrznej stronie (dla bieżącej iteracji), gdy tylko jeden wiersz zostanie wyświetlony przy łączeniu. Całkowicie możliwe jest wygenerowanie planu zapobiegającego łączeniu się bez Top. Dlaczego więc w tym planie jest najlepszy operator?
Źródło operatora Top
Aby zrozumieć, skąd pochodzi ten bezsensowny operator Top, musimy wykonać główne kroki podjęte podczas kompilacji i optymalizacji naszego przykładowego zapytania.
Jak zwykle zapytanie jest najpierw analizowane w drzewie. Zawiera logiczny operator „nie istnieje” z podzapytaniem, które w tym przypadku ściśle odpowiada pisemnej formie zapytania:

Nieistniejące podzapytanie jest rozwijane do zastosowania zapobiegającego sprzężeniu:

To jest następnie przekształcane w logiczny lewy anty-semi-join. Otrzymane drzewo przekazane do optymalizacji opartej na kosztach wygląda tak:

Pierwsza eksploracja wykonywana przez optymalizator kosztów polega na wprowadzeniu logicznego odróżnienia operacja na dolnym wejściu anti join, aby wytworzyć unikalne wartości dla klucza anti join. Ogólna idea jest taka, że zamiast testować zduplikowane wartości przy łączeniu, plan może skorzystać na grupowaniu tych wartości z góry.
Odpowiedzialna reguła eksploracji nazywa się LASJNtoLASJNonDist (lewy anty semi join do lewego anty semi join na wyraźny). Nie przeprowadzono jeszcze fizycznej implementacji ani kosztorysowania, więc jest to tylko optymalizator badający logiczną równoważność na podstawie obecności duplikatu ID produktu wartości. Nowe drzewo z dodaną operacją grupowania jest pokazane poniżej:

Następną logiczną transformacją jest przepisanie złączenia jako zastosuj . Można to zbadać za pomocą reguły LASJNtoApply (lewy anty-semi-join do zastosowania z selekcją relacyjną). Jak wspomniano wcześniej w tej serii, wcześniejsza transformacja ze stosowania na sprzężenie miała umożliwić przekształcenia, które działają konkretnie na sprzężeniach. Zawsze można przepisać sprzężenie jako zastosowanie, co rozszerza zakres dostępnych optymalizacji.
Optymalizator nie zawsze rozważ przepisanie aplikacji w ramach optymalizacji opartej na kosztach. Musi być coś w drzewie logicznym, aby warto było przesuwać predykat złączenia w dół po wewnętrznej stronie. Zazwyczaj będzie to istnienie indeksu dopasowania, ale są też inne obiecujące cele. W tym przypadku jest to klucz logiczny w ID produktu utworzone przez operację agregacji.
Wynikiem tej reguły jest skorelowane anti join z zaznaczeniem po wewnętrznej stronie:

Następnie optymalizator rozważa przeniesienie zaznaczenia relacyjnego (skorelowany predykat złączenia) dalej w dół wewnętrznej strony, poza wyróżnienie (grupowanie przez agregację) wprowadzone wcześniej przez optymalizator. Odbywa się to za pomocą reguły SelOnGbAgg , który przesuwa o tyle zaznaczenia (predykatu) poza odpowiednią grupę przez agregację, ile tylko może (część zaznaczenia może pozostać w tyle). Ta aktywność pomaga wypychać wybory jak najbliżej operatorów dostępu do danych na poziomie liścia, aby wcześniej wyeliminować wiersze i ułatwić późniejsze dopasowywanie indeksów.
W takim przypadku filtr znajduje się w tej samej kolumnie co operacja grupowania, więc transformacja jest prawidłowa. Powoduje to przesunięcie całej selekcji pod agregat:

Ostatnia operacja będąca przedmiotem zainteresowania jest wykonywana przez regułę GbAggToConstScanOrTop . Ta transformacja wygląda na zastąpienie grupa według agregacji ze stałym skanowaniem lub górą operacja logiczna. Ta reguła pasuje do naszego drzewa, ponieważ kolumna grupująca jest stała dla każdego wiersza przechodzącego przez zaznaczenie przesuwane w dół. Gwarantujemy, że wszystkie wiersze mają ten sam ID produktu . Grupowanie na tej pojedynczej wartości zawsze da jeden wiersz. W związku z tym prawidłowe jest przekształcenie agregatu w Top (1). Stąd pochodzi szczyt.
Wdrożenie i kosztorysowanie
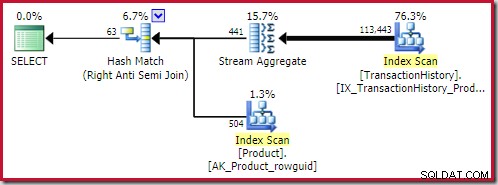
Optymalizator uruchamia teraz serię reguł implementacji, aby znaleźć operatory fizyczne dla każdej z obiecujących alternatyw logicznych, które do tej pory rozważał (przechowywanych wydajnie w strukturze notatki). Fizyczne opcje haszowania i łączenia antyjoin pochodzą z początkowego drzewa z wprowadzonym agregatem (dzięki zasadzie LASJNtoLASJNonDist Zapamiętaj). Zastosowanie wymaga trochę więcej pracy, aby zbudować fizyczny wierzchołek i dopasować zaznaczenie do wyszukiwania indeksu.
Najlepsze hash anti-join znalezione rozwiązanie kosztuje 0,362143 jednostki:
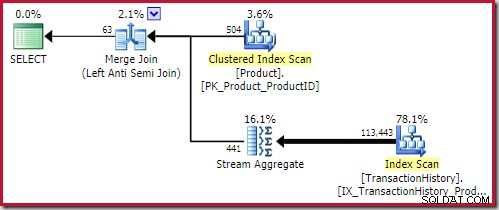
Najlepsze scalanie zapobiegające dołączaniu rozwiązanie jest dostępne w 0,353479 jednostki (nieco tańsze):
Zastosuj blokowanie łączenia kosztuje 0,091823 jednostki (najtańsze z dużym marginesem):
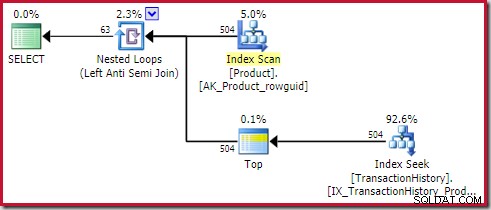
Wnikliwy czytelnik może zauważyć, że liczba wierszy po wewnętrznej stronie zastosowania anti-join (504) różni się od poprzedniego zrzutu ekranu tego samego planu. To dlatego, że jest to plan szacunkowy, podczas gdy poprzedni plan był powykonawczy. Po wykonaniu tego planu, we wszystkich iteracjach po wewnętrznej stronie znajduje się tylko 441 wierszy. Podkreśla to jedną z trudności w wyświetlaniu przy stosowaniu planów sprzężenia pół/anty:Minimalne oszacowanie optymalizatora to jeden wiersz, ale sprzężenie pół lub anty zawsze zlokalizuje jeden wiersz lub nie będzie żadnego wiersza w każdej iteracji. Przedstawione powyżej 504 wiersze reprezentują 1 wiersz w każdej z 504 iteracji. Aby liczby się zgadzały, szacunek musiałby wynosić 441/504 =0,875 wiersza za każdym razem, co prawdopodobnie równie mocno zdezorientowałoby ludzi.
W każdym razie, powyższy plan jest wystarczająco „szczęśliwy”, aby kwalifikować się do zdobycia bramki w wierszu po wewnętrznej stronie zastosowania antydołączenia z dwóch powodów:
- Anti join jest przekształcane ze złączenia w zastosowanie w optymalizatorze opartym na kosztach. To wyznacza cel rzędu (jak ustalono w części trzeciej).
- Operator Top(1) ustawia również cel wiersza w swoim poddrzewie.
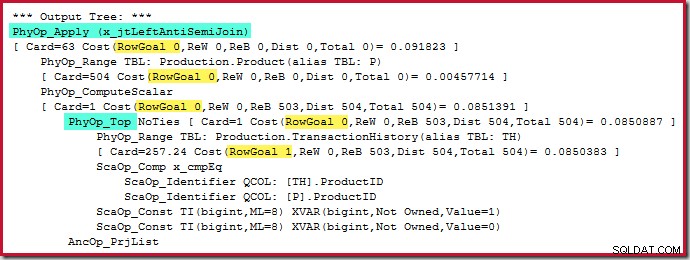
Sam operator Top nie ma celu wiersza (z zastosowania), ponieważ cel wiersza 1 byłby nie mniejszy niż zwykłe oszacowanie, które również wynosi 1 wiersz (Karta=1 dla PhyOp_Top poniżej):
Wzorzec Anti Join
Poniższy ogólny kształt planu uważam za anty-wzór:
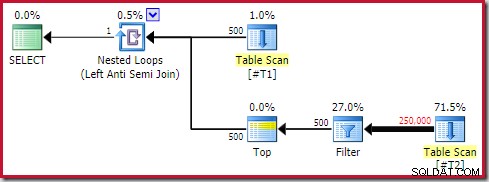
Nie każdy plan wykonania zawierający zastosowanie anti join z operatorem Top (1) po wewnętrznej stronie będzie problematyczny. Niemniej jednak jest to wzór do rozpoznania, który prawie zawsze wymaga dalszych badań.
Cztery główne elementy, na które należy zwrócić uwagę to:
- Skorelowane pętle zagnieżdżone (zastosuj ) anty łączyć
- Najlepszy (1) operator natychmiast po wewnętrznej stronie
- Znaczna liczba wierszy na wejściu zewnętrznym (więc strona wewnętrzna zostanie uruchomiona wiele razy)
- Potencjalnie drogi poddrzewo poniżej góry
Poddrzewo „$$$” to takie, które jest potencjalnie drogie w czasie wykonywania . To może być trudne do rozpoznania. Jeśli dopisze nam szczęście, pojawi się coś oczywistego, jak skan pełnej tabeli lub indeksu. W trudniejszych przypadkach poddrzewo na pierwszy rzut oka będzie wyglądać zupełnie niewinnie, ale przy bliższym przyjrzeniu się zawiera coś kosztownego. Aby podać dość powszechny przykład, możesz zobaczyć wyszukiwanie indeksu, które ma zwrócić niewielką liczbę wierszy, ale zawiera drogi predykat rezydualny, który testuje bardzo dużą liczbę wierszy, aby znaleźć kilka spełniających kryteria.
Poprzedni przykład kodu AdventureWorks nie zawierał „potencjalnie drogiego” poddrzewa. Wyszukiwanie indeksu (bez predykatu rezydualnego) byłoby optymalną metodą dostępu niezależnie od rozważań dotyczących celu wiersza. To ważna kwestia:zapewnienie optymalizatorowi zawsze wydajnego ścieżka dostępu do danych po wewnętrznej stronie sprzężenia skorelowanego jest zawsze dobrym pomysłem. Jest to jeszcze bardziej prawdziwe, gdy aplikacja działa w trybie zapobiegającym łączeniu z operatorem Top (1) po wewnętrznej stronie.
Spójrzmy teraz na przykład, który ma dość kiepską wydajność w czasie wykonywania z powodu tego wzorca anty.
Przykład
Poniższy skrypt tworzy dwie tymczasowe tabele sterty. Pierwsza ma 500 wierszy zawierających liczby całkowite od 1 do 500 włącznie. Druga tabela ma 500 kopii każdego wiersza w pierwszej tabeli, co daje łącznie 250 000 wierszy. Obie tabele używają sql_variant typ danych.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Wydajność
Teraz uruchamiamy zapytanie, szukając wierszy w mniejszej tabeli, których nie ma w większej tabeli (oczywiście nie ma żadnych):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); To zapytanie trwa około 20 sekund , co jest strasznie długim czasem na porównanie 500 wierszy z 250 000. Szacunkowy plan SSMS sprawia, że trudno jest zrozumieć, dlaczego wydajność może być tak niska:
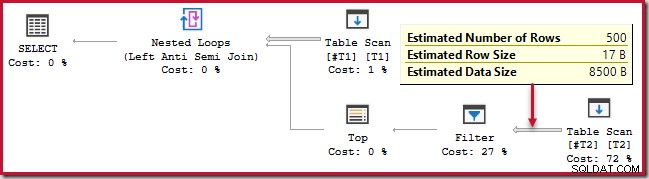
Obserwator musi mieć świadomość, że szacunkowe plany SSMS pokazują wewnętrzne szacunki na iterację zagnieżdżonego sprzężenia w pętli. Mylące, rzeczywiste plany SSMS pokazują liczbę wierszy w wszystkich iteracjach . Plan Explorer automatycznie wykonuje proste obliczenia niezbędne do szacowania planów, aby pokazać również całkowitą oczekiwaną liczbę wierszy:
Mimo to wydajność środowiska wykonawczego jest znacznie gorsza niż szacowano. Powykonawczy (rzeczywisty) plan wykonania to:
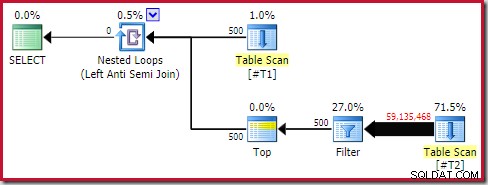
Zwróć uwagę na oddzielny filtr, który normalnie zostałby przesunięty do skanowania jako predykat rezydualny. To jest powód używania sql_variant typ danych; zapobiega przesuwaniu predykatu, co sprawia, że ogromna liczba wierszy ze skanowania jest łatwiej widoczna.
Analiza
Przyczyna rozbieżności sprowadza się do tego, w jaki sposób optymalizator szacuje liczbę wierszy, które będzie musiał odczytać ze skanowania tabeli, aby osiągnąć cel jednego wiersza ustawiony w filtrze. Proste założenie jest takie, że wartości są równomiernie rozmieszczone w tabeli, więc aby napotkać 1 z 500 obecnych wartości unikatowych, SQL Server będzie musiał odczytać 250 000 / 500 =500 wierszy. Ponad 500 iteracji, co daje 250 000 wierszy.
Założenie jednolitości optymalizatora jest ogólne, ale tutaj nie działa dobrze. Więcej informacji na ten temat można znaleźć w artykule Joe Obbish Prośba o cel rzędu rzędu, a także zagłosować na jego sugestię na forum opinii dotyczących wymiany produktów Connect pod adresem Użyj większej niż gęstość, aby kosztować skanowanie po wewnętrznej stronie zagnieżdżonej pętli z TOP.
Mój pogląd na ten konkretny aspekt jest taki, że optymalizator powinien szybko wycofać się z prostego założenia jednolitości, gdy operator znajduje się po wewnętrznej stronie złączenia zagnieżdżonych pętli (tj. szacowane przewinięcia i ponowne wiązania są większe niż jeden). Jedną rzeczą jest założenie, że musimy przeczytać 500 wierszy, aby znaleźć dopasowanie w pierwszej iteracji pętli. Założenie tego w każdej iteracji wydaje się strasznie mało prawdopodobne; oznacza to, że pierwsze 500 napotkanych wierszy powinno zawierać jedną z każdej odrębnej wartości. Jest to wysoce nieprawdopodobne w praktyce.
Seria niefortunnych zdarzeń
Niezależnie od kosztów powtarzanych Top operatorów, wydaje mi się, że całej sytuacji należy przede wszystkim unikać . Przypomnij sobie, jak utworzono Top w tym planie:
- Optymalizator wprowadził odrębną agregację po wewnętrznej stronie jako optymalizację wydajności .
- Ta agregacja z definicji zapewnia klucz w kolumnie sprzężenia (daje unikatowość).
- Ten skonstruowany klucz stanowi cel konwersji sprzężenia na zastosowanie.
- Predykat (wybór) powiązany z zastosowaniem jest przesuwany w dół poza agregat.
- Gwarantuje się teraz, że agregat będzie działał na pojedynczej odrębnej wartości na iterację (ponieważ jest to wartość korelacji).
- Agregacja zostaje zastąpiona przez Top (1).
Wszystkie te przekształcenia obowiązują indywidualnie. Są one częścią normalnych operacji optymalizatora, ponieważ wyszukuje on rozsądny plan wykonania. Niestety w wyniku tego, spekulacyjna agregacja wprowadzona przez optymalizator zostaje przekształcona w Top (1) z powiązanym celem w wierszu . Cel rzędu prowadzi do niedokładnego kalkulacji kosztów w oparciu o założenie jednolitości, a następnie do wyboru planu, który jest mało prawdopodobny.
Teraz można by sprzeciwić się temu, że zastosowanie anty sprzężenia i tak miałoby cel wiersza – bez powyższej sekwencji przekształceń. Kontrargumentem jest to, że optymalizator nie rozważyłby transformacja z antijoin na zastosuj anti join (ustawianie celu wiersza) bez wprowadzonej przez optymalizator agregacji dającej LASJNtoApply rządzić czymś, z czym można się związać. Ponadto widzieliśmy (w części trzeciej), że gdyby anty złączenie zostało wprowadzone jako zastosowanie optymalizacji opartej na kosztach (zamiast złączenia), ponownie byłoby brak celu wiersza .
Krótko mówiąc, cel wiersza w ostatecznym planie jest całkowicie sztuczny i nie ma podstaw w oryginalnej specyfikacji zapytania. Problem z celem Top i wierszem jest efektem ubocznym tego bardziej podstawowego aspektu.
Obejścia
Istnieje wiele potencjalnych rozwiązań tego problemu. Usunięcie któregokolwiek z kroków w powyższej sekwencji optymalizacji zapewni, że optymalizator nie wygeneruje implementacji zapobiegającej łączeniu z zastosowaniem drastycznie (i sztucznie) obniżonych kosztów. Mamy nadzieję, że ten problem zostanie rozwiązany w SQL Server raczej wcześniej niż później.
W międzyczasie radzę uważać na wzór anty sprzężeń. Upewnij się, że wewnętrzna strona zastosowanego połączenia zabezpieczającego zawsze ma wydajną ścieżkę dostępu dla wszystkich warunków środowiska wykonawczego. Jeśli nie jest to możliwe, konieczne może być skorzystanie z podpowiedzi, wyłączenie celów wierszy, skorzystanie z przewodnika po planie lub wymuszenie na planie magazynu zapytań uzyskania stabilnej wydajności zapytań zapobiegających sprzężeniu.
Podsumowanie serii
W czterech ratach omówiliśmy wiele rzeczy, więc oto podsumowanie na wysokim poziomie:
- Część 1 – Ustalanie i identyfikacja celów wierszy
- Składnia zapytania nie określa obecności lub braku celu wiersza.
- Cel wiersza jest ustawiany tylko wtedy, gdy cel jest niższy niż zwykłe oszacowanie.
- Fizyczne operatory Top (w tym te wprowadzone przez optymalizator) dodają cel wiersza do swojego poddrzewa.
FASTlubSET ROWCOUNToświadczenie ustawia cel rzędu u podstawy planu.- Dołączanie częściowo i przeciw może dodaj cel wiersza.
- SQL Server 2017 CU3 dodaje atrybut showplan EstimateRowsWithoutRowGoal dla operatorów, których dotyczy cel wiersza
- Informacje o celu wiersza mogą być ujawnione przez nieudokumentowane flagi śledzenia 8607 i 8612.
- Część 2 – Częściowe sprzężenia
- Nie jest możliwe wyrażenie semijoin bezpośrednio w T-SQL, dlatego używamy składni pośredniej, np.
IN,EXISTSlubINTERSECT. - Te składnie są analizowane w drzewie zawierającym zastosowanie (skorelowane złączenie).
- Optymalizator próbuje przekształcić zastosowanie w zwykłe złączenie (nie zawsze jest to możliwe).
- Hash, merge i regularne zagnieżdżone pętle semi-join nie ustawiają celu wiersza.
- Zastosuj sprzężenie częściowe zawsze ustawia cel wiersza.
- Zastosowanie sprzężenia częściowego może być rozpoznane dzięki odnośnikom zewnętrznym na operatorze łączenia zagnieżdżonych pętli.
- Zastosuj sprzężenie częściowe nie używa operatora Top (1) po wewnętrznej stronie.
- Część 3 – Zapobieganie łączeniom
- Również przetworzone na zastosowanie, z próbą przepisania tego jako sprzężenia (nie zawsze możliwe).
- Hash, merge i regularne zagnieżdżone pętle zapobiegające łączeniu nie ustawiają celu wiersza.
- Zastosuj blokowanie łączenia nie zawsze ustawia cel wiersza.
- Tylko reguły optymalizacji opartej na kosztach (CBO), które przekształcają anty sprzężenia w celu zastosowania, ustawiają cel wiersza.
- Złączenie anty musi wprowadzić CBO jako złączenie (nie dotyczy). W przeciwnym razie złączenie w celu zastosowania przekształcenia nie może nastąpić.
- Aby wejść do CBO jako dołączenie, przepisanie pre-CBO z zastosowania na dołączenie musi się udać.
- CBO analizuje przepisywanie anty-join do aplikacji tylko w obiecujących przypadkach.
- Uproszczenia przed CBO można przeglądać za pomocą nieudokumentowanej flagi śledzenia 8621.
- Część 4 – Wzorzec zapobiegający łączeniu się
- Optymalizator wyznacza cel wiersza dla zastosowania anty sprzężenia tylko wtedy, gdy istnieje ku temu obiecujący powód.
- Niestety, wiele oddziałujących na siebie przekształceń optymalizujących dodaje operator Top (1) po wewnętrznej stronie zastosowania anti join.
- Operator Top jest nadmiarowy; nie jest to wymagane dla poprawności lub wydajności.
- Najlepszy zawsze wyznacza cel rzędu (w przeciwieństwie do zastosowania, co wymaga dobrego powodu).
- Nieuzasadniony cel w wierszu może prowadzić do wyjątkowo słabej wydajności.
- Uważaj na potencjalnie drogie poddrzewo pod sztucznym wierzchołkiem (1).