Niedawno napisałem post o DISTINCT i GROUP BY. Było to porównanie, które wykazało, że GROUP BY jest generalnie lepszą opcją niż DISTINCT. Jest na innej stronie, ale pamiętaj, aby zaraz potem wrócić na sqlperformance.com.
Jedno z porównań zapytań, które pokazałem w tym poście, dotyczyło GROUP BY i DISTINCT dla podzapytania, pokazując, że DISTINCT jest znacznie wolniejsze, ponieważ musi raczej pobrać nazwę produktu dla każdego wiersza w tabeli Sales niż tylko dla każdego innego ProductID. Jest to całkiem oczywiste z planów zapytań, gdzie widać, że w pierwszym zapytaniu Aggregate operuje na danych z tylko jednej tabeli, a nie na wynikach sprzężenia. Aha, a oba zapytania dają te same 266 wierszy.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

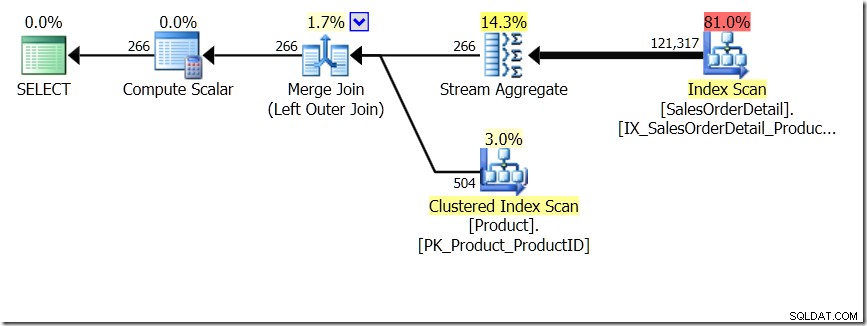
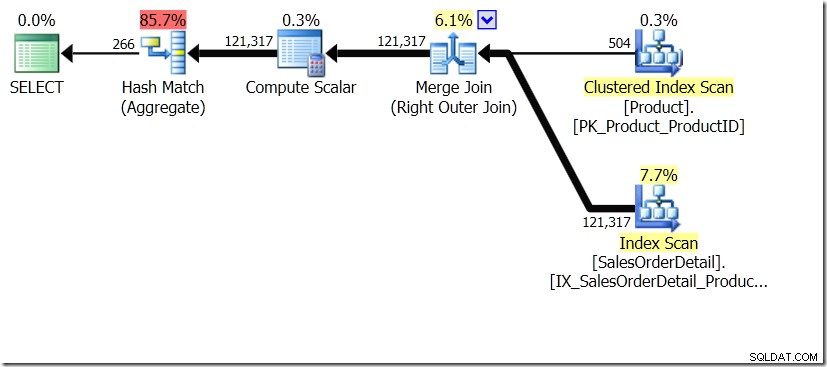
Teraz, m.in. przez Adama Machanica (@adammachanic) w tweecie odnoszącym się do posta Aarona o GROUP BY v DISTINCT, te dwa zapytania są zasadniczo różne, że w rzeczywistości prosi się o zestaw różnych kombinacji wyników podzapytanie, zamiast uruchamiać podzapytanie w różnych przekazywanych wartościach. To właśnie widzimy w planie i jest to powód, dla którego wydajność jest tak różna.
Chodzi o to, że wszyscy zakładamy, że wyniki będą identyczne.
Ale to założenie i nie jest dobre.
Wyobrażam sobie przez chwilę, że Optymalizator zapytań wymyślił inny plan. Użyłem wskazówek, ale jak wiesz, Optymalizator zapytań może tworzyć plany o różnych kształtach z różnych powodów.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
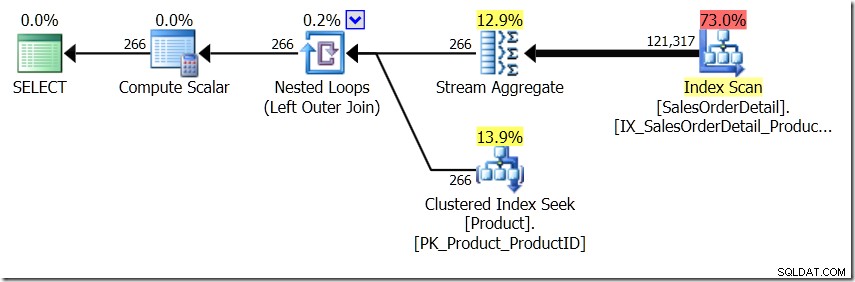
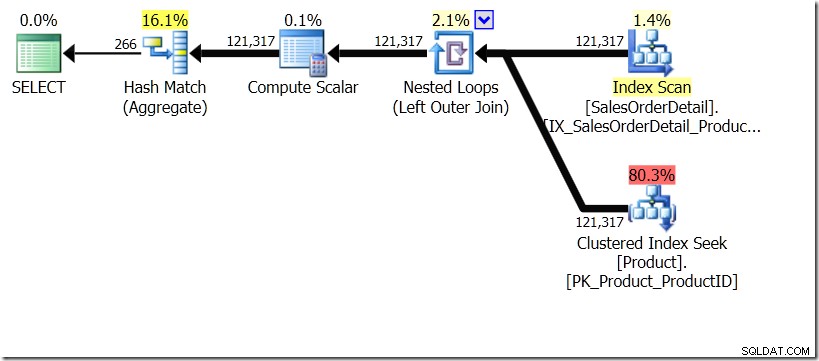
W tej sytuacji wykonujemy 266 wyszukiwania w tabeli Product, po jednym dla każdego innego identyfikatora produktu, który nas interesuje, lub 121.317 Seeks. Jeśli więc myślimy o konkretnym ProductID, wiemy, że otrzymamy jedną nazwę z powrotem z pierwszego. I zakładamy, że otrzymamy z powrotem jedną nazwę dla tego identyfikatora produktu, nawet jeśli będziemy musieli o to prosić sto razy. Po prostu zakładamy, że uzyskamy te same wyniki.
Ale co, jeśli tego nie zrobimy?
Brzmi to jak kwestia poziomu izolacji, więc użyjmy NOLOCK, gdy trafimy na tabelę Product. I uruchommy (w innym oknie) skrypt zmieniający tekst w kolumnach Nazwa. Będę to robił w kółko, aby spróbować uzyskać niektóre zmiany między moimi zapytaniami.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Teraz moje wyniki są inne. Plany są takie same (z wyjątkiem liczby wierszy wychodzących z funkcji Hash Aggregate w drugim zapytaniu), ale moje wyniki są inne.
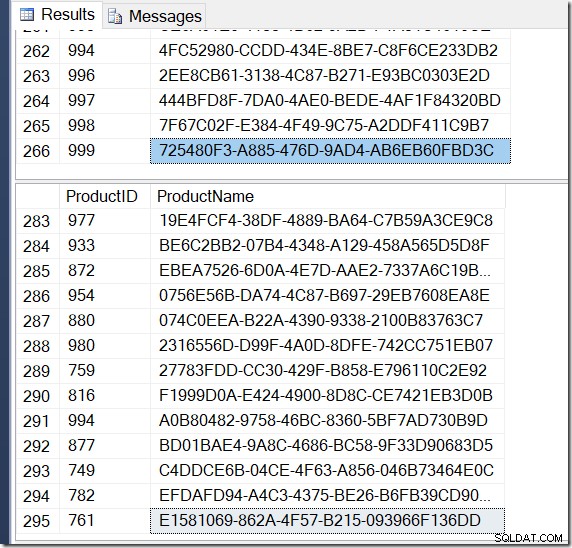
Rzeczywiście, mam więcej wierszy z DISTINCT, ponieważ znajduje różne wartości Name dla tego samego ProductID. I niekoniecznie mam 295 wierszy. Kolejny, kiedy to uruchomię, może dostanę 273 lub 300, a może 121 317.
Nie jest trudno znaleźć przykład identyfikatora produktu, który pokazuje wiele wartości nazwy, potwierdzając, co się dzieje.

Oczywiście, aby upewnić się, że nie widzimy tych wierszy w wynikach, musimy albo NIE używać DISTINCT, albo użyć bardziej rygorystycznego poziomu izolacji.
Rzecz w tym, że chociaż wspomniałem o używaniu NOLOCK w tym przykładzie, nie musiałem. Taka sytuacja występuje nawet w przypadku READ COMMITTED, który jest domyślnym poziomem izolacji w wielu systemach SQL Server.
Widzisz, potrzebujemy poziomu izolacji ODCZYT POWTARZALNY, aby uniknąć tej sytuacji, aby utrzymać blokady w każdym wierszu po jego odczytaniu. W przeciwnym razie oddzielny wątek może zmienić dane, jak widzieliśmy.
Ale… nie mogę pokazać, że wyniki są naprawione, ponieważ nie udało mi się uniknąć impasu w zapytaniu.
Zmieńmy więc warunki, upewniając się, że nasze drugie zapytanie nie stanowi większego problemu. Zamiast aktualizować całą tabelę na raz (co i tak jest znacznie mniej prawdopodobne w prawdziwym świecie), zaktualizujmy tylko jeden wiersz na raz.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Teraz nadal możemy zademonstrować problem na niższym poziomie izolacji, takim jak READ COMMITTED lub READ UNCOMMITTED (chociaż może być konieczne wielokrotne uruchomienie zapytania, jeśli uzyskasz 266 za pierwszym razem, ponieważ istnieje szansa na aktualizację wiersza podczas zapytania jest mniej), a teraz możemy wykazać, że REPEATABLE READ naprawia to (niezależnie od tego, ile razy uruchomimy zapytanie).
POWTARZALNE CZYTANIE robi to, co jest napisane na puszce. Po odczytaniu wiersza w transakcji jest on blokowany, aby upewnić się, że możesz powtórzyć odczyt i uzyskać te same wyniki. Mniejsze poziomy izolacji nie usuwają tych blokad, dopóki nie spróbujesz zmienić danych. Jeśli Twój plan zapytań nigdy nie musi powtarzać odczytu (jak ma to miejsce w przypadku kształtu naszych planów GROUP BY), nie będziesz potrzebować POWTARZALNEGO ODCZYTU.
Zapewne zawsze powinniśmy używać wyższych poziomów izolacji, takich jak REPEATABLE READ lub SERIALIZABLE, ale wszystko sprowadza się do ustalenia, czego potrzebują nasze systemy. Te poziomy mogą wprowadzać niechciane blokowanie, a poziomy izolacji SNAPSHOT wymagają wersji, która również ma swoją cenę. Dla mnie myślę, że to kompromis. Jeśli pytam o zapytanie, na które może mieć wpływ zmiana danych, być może będę musiał na chwilę podnieść poziom izolacji.
W idealnym przypadku po prostu nie aktualizujesz danych, które właśnie zostały odczytane i mogą wymagać ponownego odczytania podczas zapytania, dzięki czemu nie potrzebujesz POWTARZALNEGO ODCZYTU. Ale zdecydowanie warto zrozumieć, co może się wydarzyć, i uznać, że jest to rodzaj scenariusza, w którym DISTINCT i GROUP BY mogą nie być takie same.
@rob_farley