IGNORE_DUP_KEY opcja dla unikalnych indeksów określa, jak SQL Server odpowiada na próbę INSERT zduplikowane wartości:dotyczy tylko tabel (nie widoków) i tylko wstawek. Dowolna wstawiana część MERGE instrukcja ignoruje każdy IGNORE_DUP_KEY ustawienie indeksu.
Kiedy IGNORE_DUP_KEY jest OFF , pierwszy napotkany duplikat powoduje błąd i żaden z nowych wierszy nie jest wstawiany.
Kiedy IGNORE_DUP_KEY jest ON , wstawione wiersze, które naruszałyby unikalność, są odrzucane. Pozostałe wiersze zostały pomyślnie wstawione. ostrzeżenie zamiast błędu jest emitowany komunikat:
Podsumowanie artykułu
IGNORE_DUP_KEY opcję index można określić zarówno dla unikatowych indeksów klastrowych, jak i nieklastrowanych. Używanie go w indeksie klastrowym może skutkować znacznie gorszą wydajnością niż dla unikatowego indeksu nieklastrowanego.
Wielkość różnicy wydajności zależy od tego, ile naruszeń unikalności napotkano podczas INSERT operacja. Im więcej naruszeń, tym gorzej wypada klastrowany unikalny indeks w porównaniu. Jeśli nie ma żadnych naruszeń, wstawianie indeksu klastrowego może nawet działać lepiej.
Unikalne wstawki indeksowe w klastrach
Dla klastrowego unikalnego indeksu z IGNORE_DUP_KEY ustawiony, duplikaty są obsługiwane przez silnik pamięci .
Wiele prac związanych z wstawianiem każdego wiersza jest wykonywanych przed wykryciem duplikatu. Na przykład wstawka z indeksem klastrowym operator nawiguje w dół klastrowego indeksu b-drzewa do punktu, w którym znajdzie się nowy wiersz, biorąc zatrzaski stron i zwykłą hierarchię blokad, zanim wykryje zduplikowany klucz.
Po wykryciu warunku zduplikowanego klucza pojawia się błąd jest podniesiony. Zamiast anulować wykonanie i zwrócić błąd do klienta, błąd jest obsługiwany wewnętrznie. Problematyczny wiersz nie jest wstawiany, a wykonywanie jest kontynuowane w poszukiwaniu następnego wiersza do wstawienia. Jeśli ten wiersz napotka zduplikowany klucz, zgłaszany i obsługiwany jest kolejny błąd i tak dalej.
Rzucanie i łapanie wyjątków jest bardzo drogie. Znaczna liczba duplikatów znacznie spowolni wykonanie.
Nieklastrowane unikatowe wstawki indeksowe
Dla nieklastrowanego unikalnego indeksu z IGNORE_DUP_KEY ustawiony, duplikaty są obsługiwane przez procesor zapytań . Wykrywane są duplikaty i emitowane jest ostrzeżenie przed każdą próbą wstawienia.
Procesor zapytań usuwa duplikaty ze strumienia wstawiania, zapewniając, że żadne duplikaty nie są widoczne dla aparatu magazynu. W rezultacie żadne unikatowe błędy naruszenia klucza nie są zgłaszane ani obsługiwane wewnętrznie.
Kompromis
Istnieje kompromis między kosztem wykrycia i usunięcia zduplikowanych kluczy w planie wykonania a kosztem wykonania znacznej pracy związanej z wstawianiem oraz zgłaszaniem i wyłapywaniem błędów po znalezieniu duplikatu.
Jeśli oczekuje się, że duplikaty będą bardzo rzadkie , rozwiązanie silnika pamięci masowej (indeks klastrowy) może być bardziej wydajne. Gdy duplikaty są mniej rzadkie, podejście procesora zapytań prawdopodobnie przyniesie korzyści. Dokładny punkt przecięcia będzie zależał od takich czynników, jak wydajność środowiska wykonawczego komponentów planu wykonania używanych do wykrywania i usuwania duplikatów.
Pozostała część tego artykułu zawiera demonstrację i bardziej szczegółowo wyjaśnia, dlaczego podejście silnika pamięci masowej może działać tak słabo.
Demo
Poniższy skrypt tworzy tabelę tymczasową z milionem wierszy. Ma 1000 unikalnych wartości i 1000 wierszy dla każdej unikalnej wartości. Ten zestaw danych będzie używany jako źródło danych do wstawiania do tabel z różnymi konfiguracjami indeksów.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Podstawa
Poniższa wstawka do zmiennej tabeli z nieunikalnym indeksem klastrowym zajmuje około 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Zwróć uwagę na brak IGNORE_DUP_KEY w zmiennej tabeli docelowej.
Unikalny indeks klastrowy
Wstawianie tych samych danych do unikalnego klastra indeksuj za pomocą IGNORE_DUP_KEY ustaw ON trwa około 15 900 ms — prawie 18 razy gorzej:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Unikalny indeks nieklastrowany
Wstawianie danych do unikalnego nieklastrowanego indeksuj za pomocą IGNORE_DUP_KEY ustaw ON trwa około 700ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Podsumowanie wyników
Test podstawowy trwa 900 ms aby wstawić cały milion wierszy. Test indeksu nieklastrowego trwa 700 ms aby wstawić tylko 1000 odrębnych kluczy. Test indeksu klastrowego trwa 15 900 ms aby wstawić te same 1000 unikalnych wierszy.
Ten test został celowo skonfigurowany w celu podkreślenia słabej wydajności implementacji silnika pamięci masowej, generując 999 jednostek zmarnowanej pracy (zatrzaski, blokady, obsługa błędów) dla każdego udanego wiersza.
Zamierzona wiadomość to nie ten IGNORE_DUP_KEY zawsze będzie działać słabo na indeksach klastrowanych, tylko że może, i może być duża różnica między indeksami klastrowanymi i nieklastrowanymi.
Plan wykonania indeksu klastrowego
Nie ma dużej ilości do zobaczenia w planie wstawiania indeksu klastrowego:
1 000 000 wierszy jest przekazywanych do wstawki indeksu klastrowego operator, który jest wyświetlany jako „zwracający” 1000 wierszy. Zagłębiając się w szczegóły planu, możemy zobaczyć:
- 1 244 008 odczytów logicznych na operatorze wstawiania.
- Ogromna większość czasu wykonania jest poświęcana na Wstaw operator.
- 11 ms
SOS_SCHEDULER_YIELDczeka (tj. żadne inne czeka).
Nic, co naprawdę wyjaśnia 15 900 ms upływu czasu.
Dlaczego wydajność jest tak niska
Oczywiste jest, że ten plan będzie wymagał dużo pracy dla każdego rzędu:
- Nawiguj po poziomach b-drzewa indeksu klastrowego, zatrzaskując i blokując, aby znaleźć punkt wstawiania dla nowego rekordu.
- Jeśli którakolwiek z potrzebnych stron indeksu nie znajduje się w pamięci, należy je pobrać z dysku.
- Zbuduj nowy wiersz b-drzewa w pamięci.
- Przygotuj zapisy dziennika.
- Jeśli zostanie znaleziony duplikat klucza (który nie jest rekordem ducha), zgłoś błąd, obsłuż go wewnętrznie, zwolnij bieżący wiersz i wznów w odpowiednim punkcie kodu, aby przetworzyć następny wiersz kandydujący.
To sporo pracy i pamiętaj, że wszystko dzieje się dla każdego wiersza .
Część, na której chcę się skoncentrować, to podnoszenie i obsługa błędów, ponieważ jest to niezwykle kosztowny. Pozostałe aspekty wymienione powyżej zostały już tak tanie, jak to tylko możliwe, dzięki użyciu zmiennej tabeli i tabeli tymczasowej w wersji demonstracyjnej.
Wyjątki
Pierwszą rzeczą, którą chcę zrobić, to pokazać, że wstawka z indeksem klastrowym operator naprawdę zgłasza wyjątek, gdy napotka zduplikowany klucz.
Jednym ze sposobów, aby pokazać to bezpośrednio, jest dołączenie debugera i przechwycenie śladu stosu w punkcie, w którym zgłoszony jest wyjątek:
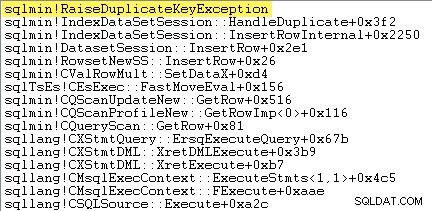
Ważną kwestią jest to, że rzucanie i łapanie wyjątków jest bardzo drogie.
Monitorowanie SQL Server za pomocą Rejestratora wydajności systemu Windows podczas wykonywania testu i analizowanie wyników w Analizatorze wydajności systemu Windows pokazuje:
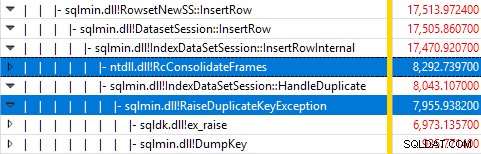
Prawie cały czas wykonania zapytania jest spędzany w sqlmin!IndexDataSetSession::InsertRowInternal jak można by się spodziewać po zapytaniu, które robi niewiele poza wstawianiem wierszy.
Niespodzianką jest to, że 45% tego czasu poświęca się na zgłaszanie wyjątków za pomocą sqlmin!RaiseDuplicateKeyException a kolejne 47% jest wydawane na powiązany blok przechwytywania wyjątków (ntdll!RcConsolidateFrames hierarchia).
Podsumowując:zgłaszanie i łapanie wyjątków stanowi 92% czasu wykonania naszego testowego zapytania wstawiania indeksu klastrowego.
Problemy z gromadzeniem danych
Bystrzy czytelnicy mogą zauważyć znaczną część – około 12% – czasu na zgłaszanie wyjątków spędzonego w sqlmin!DumpKey na grafice analizatora wydajności systemu Windows. Warto to szybko zbadać wraz z kilkoma powiązanymi elementami.
W ramach zgłaszania wyjątku SQL Server musi zebrać pewne dane, które są dostępne tylko w momencie wystąpienia błędu. Numer błędu związany z wyjątkiem zduplikowanego klucza to 2627. Tekst komunikatu w sys.messages numer błędu to:
Informacje do wypełnienia tych znaczników miejsc muszą być zebrane w momencie pojawienia się błędu — nie będą dostępne później! Oznacza to wyszukanie i sformatowanie typu ograniczenia, jego nazwy, pełnej nazwy obiektu docelowego i określonej wartości klucza. Wszystko to wymaga czasu.
Poniższy ślad stosu pokazuje serwer formatujący zduplikowaną wartość klucza jako ciąg Unicode podczas DumpKey zadzwoń:
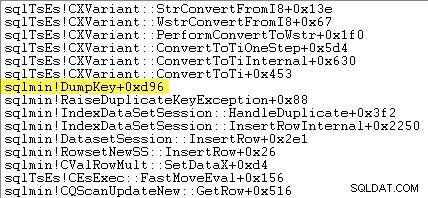
Obsługa wyjątków obejmuje również przechwytywanie śladu stosu:
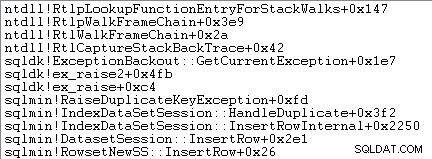
SQL Server rejestruje również informacje o wyjątkach (w tym ramkach stosu) w małym buforze pierścieniowym, jak pokazano poniżej:
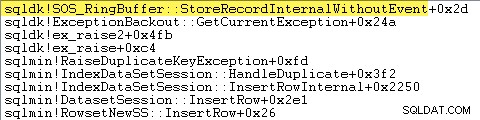
Możesz zobaczyć te wpisy bufora pierścieniowego za pomocą polecenia takiego jak:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Poniżej znajduje się przykład rekordu XML dla wyjątku zduplikowanego klucza. Zwróć uwagę na ramki stosu:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Cała ta praca w tle dzieje się dla każdego wyjątku. W naszym teście oznacza to, że dzieje się to 999 000 razy — raz na każdy wiersz, który napotka zduplikowane naruszenie klucza.
Można to zobaczyć na wiele sposobów, na przykład uruchamiając śledzenie Profiler przy użyciu Wyjątku zdarzenie w Błędy i ostrzeżenia klasa. W naszym przypadku testowym ostatecznie utwórz 999 000 wierszy za pomocą TextData elementy takie jak:
Naruszenie ograniczenia UNIQUE KEY 'UQ__#AC166DE__3213663B8B6E2E0E'Nie można wstawić zduplikowanego klucza w obiekcie 'dbo.@T'.
Wartość zduplikowanego klucza to (173).
Dołączanie programu Profiler oznacza, że każde zdarzenie obsługi wyjątków wiąże się z dużym dodatkowym obciążeniem, ponieważ potrzebne są dodatkowe dane, które są gromadzone i formatowane. Wspomniane wcześniej domyślne dane są zawsze gromadzone, nawet jeśli nikt nie wykorzystuje aktywnie tych informacji.
Dla jasności:wszystkie dane dotyczące wydajności podane w tym artykule zostały uzyskane bez dołączonego debugera i bez aktywnego monitorowania.
Plan wykonania indeksu bezklastrowego
Pomimo tego, że jest o wiele szybszy, plan wstawiania indeksów bez klastrów jest nieco bardziej złożony, więc podzielę go na dwie części.
Ogólnym tematem jest to, że ten plan jest szybszy, ponieważ eliminuje duplikaty przed próbując wstawić je do tabeli docelowej.
Część 1
Najpierw prawa strona planu indeksowania nieklastrowanego:
Ta część planu odrzuca wszystkie wiersze, które mają dopasowanie klucza w tabeli docelowej dla unikalnego indeksu z IGNORE_DUP_KEY ustaw ON .
Możesz spodziewać się Anti Semi Join tutaj, ale SQL Server nie ma niezbędnej infrastruktury, aby emitować wymagane ostrzeżenie o zduplikowanym kluczu z Anti Semi Join operator. (Jeśli to nie ma sensu, powinno wkrótce.)
Zamiast tego otrzymujemy plan z wieloma interesującymi funkcjami:
- Skanowanie indeksu klastrowego jest
Ordered:Truew celu zapewnienia danych wejściowych do połączenia lewego łączenia częściowego posortowane według kolumnyc1w#Datastół. - Skanowanie indeksu zmiennej tabeli jest
Ordered:False - Sortuj porządkuje wiersze według kolumny
c1w zmiennej tabeli. To zamówienie mogło zostać dostarczone przez zamówione skanowanie indeksu zmiennej tabeli nac1, ale optymalizator decyduje o sortowaniu to najtańszy sposób na zapewnienie wymaganego poziomu ochrony Halloween. - Zmienna tabeli Skanowanie indeksu ma wewnętrzny
UPDLOCKiSERIALIZABLEpodpowiedzi zastosowane w celu zapewnienia stabilności celu podczas wykonywania planu. - Scalanie lewego połączenia częściowego sprawdza dopasowania w zmiennej tabeli dla każdej wartości
c1zwrócone z#Datastół. W przeciwieństwie do zwykłego sprzężenia semi, emituje każdy wiersz odebrany na jego górnym wejściu. Ustawia flagę w kolumnie sondy aby wskazać, czy bieżący wiersz znalazł dopasowanie, czy nie. Kolumna sondująca jest emitowana przez Merge Left Semi Join jako wyrażenie o nazwieExpr1012. - Zatwierdzenie operator sprawdza wartość kolumny sondy
Expr1012. Gdy po raz pierwszy zobaczy wiersz z wartością kolumny sondy innej niż null (co wskazuje, że znaleziono dopasowanie klucza indeksu), emituje komunikat „Duplikat klucza został zignorowany” wiadomość. - Zatwierdzenie przekazuje tylko wiersze, w których kolumna sondy ma wartość null. Eliminuje to przychodzące wiersze, które powodowałyby zduplikowany błąd klucza.
To wszystko może wydawać się skomplikowane, ale zasadniczo jest to tak proste, jak ustawienie flagi, jeśli zostanie znalezione dopasowanie, emitowanie ostrzeżenia przy pierwszym ustawieniu flagi i przekazywanie tylko wierszy do wstawienia, które jeszcze nie istnieją w tabeli docelowej .
Część 2
Druga część planu jest zgodna z Atencją operator:
Poprzednia część planu usunęła wiersze, które pasowały do tabeli docelowej. Ta część planu usuwa duplikaty w zestawie wstawek .
Na przykład wyobraź sobie, że w tabeli docelowej nie ma wierszy, w których c1 = 1 . Nadal możemy spowodować błąd zduplikowanego klucza, jeśli spróbujemy wstawić dwa wiersze z c1 = 1 z tabeli źródłowej. Musimy tego uniknąć, aby uszanować semantykę IGNORE_DUP_KEY = ON .
Ten aspekt jest obsługiwany przez Segment i Góra operatorów.
Segment operator ustawia nową flagę (oznaczoną Segment1015 ), gdy napotka wiersz z nową wartością dla c1 . Ponieważ wiersze są prezentowane w c1 zamówienie (dzięki zachowaniu kolejności Scal ), plan może polegać na wszystkich wierszach z tym samym c1 wartość przybywająca w ciągłym strumieniu.
Góra operator przekazuje jeden wiersz dla każdej grupy duplikatów, jak wskazuje Segment flaga. Jeśli Góra operator napotyka więcej niż jeden wiersz dla tego samego segmentu grupa (c1 wartość), emituje komunikat „Zduplikowany klucz został zignorowany” ostrzeżenie, jeśli to jest pierwszy raz, kiedy plan napotkał ten stan.
Efektem tego wszystkiego jest to, że tylko jeden wiersz jest przekazywany do operatorów wstawiania dla każdej unikalnej wartości c1 , aw razie potrzeby generowane jest ostrzeżenie.
Plan wykonania wyeliminował teraz wszystkie potencjalne naruszenia zduplikowanych kluczy, więc pozostałe wstawka do tabeli i Wstawka indeksująca operatorzy mogą bezpiecznie wstawiać wiersze do sterty i indeksu nieklastrowanego bez obawy o zduplikowany błąd klucza.
Pamiętaj, że UPDLOCK i SERIALIZABLE wskazówki zastosowane do tabeli docelowej zapewniają, że zestaw nie może ulec zmianie podczas wykonywania. Innymi słowy, współbieżna instrukcja nie może zmienić tabeli docelowej w taki sposób, że przy Wstaw wystąpiłby błąd zduplikowanego klucza. operatorów. Nie stanowi to problemu, ponieważ używamy prywatnej zmiennej tabeli, ale SQL Server nadal dodaje wskazówki jako ogólny środek bezpieczeństwa.
Bez tych wskazówek współbieżny proces mógłby dodać wiersz do tabeli docelowej, co spowodowałoby zduplikowane naruszenie klucza, pomimo kontroli wykonanych w części 1 planu. SQL Server musi mieć pewność, że wyniki sprawdzenia istnienia pozostają ważne.
Ciekawy czytelnik może zobaczyć niektóre z funkcji opisanych powyżej, włączając flagi śledzenia 3604 i 8607, aby zobaczyć drzewo wyjściowe optymalizatora:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Końcowe myśli
IGNORE_DUP_KEY Opcja indeksu nie jest czymś, z czego większość ludzi korzysta bardzo często. Mimo to warto przyjrzeć się, jak ta funkcjonalność jest zaimplementowana i dlaczego mogą występować duże różnice w wydajności między IGNORE_DUP_KEY na indeksach klastrowych i nieklastrowych.
W wielu przypadkach opłaca się podążać za przykładem procesora zapytań i dążyć do pisania zapytań, które wyraźnie eliminują duplikaty, zamiast polegać na IGNORE_DUP_KEY . W naszym przykładzie oznaczałoby to napisanie:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; To trwa około 400ms , tylko dla przypomnienia.