Miałem ostatnio wiele rozmów na temat rodzajów obciążeń – w szczególności zrozumienia, czy obciążenie jest sparametryzowane, adhoc czy mieszane. Jest to jedna z rzeczy, na które zwracamy uwagę podczas audytu stanu zdrowia, a Kimberly ma świetne zapytanie z pamięci podręcznej planów i optymalizację pod kątem obciążeń adhoc, które są częścią naszego zestawu narzędzi. Skopiowałem poniższe zapytanie i jeśli nigdy wcześniej nie uruchamiałeś go w żadnym ze swoich środowisk produkcyjnych, zdecydowanie znajdź na to trochę czasu.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Jeśli uruchomię to zapytanie w środowisku produkcyjnym, możemy otrzymać dane wyjściowe takie jak:
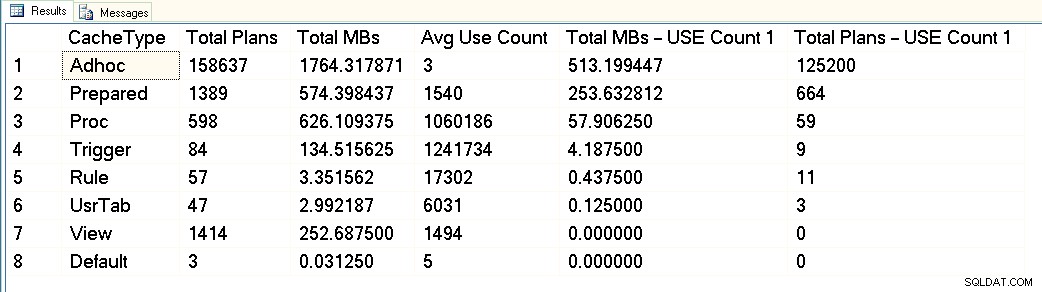
Na tym zrzucie ekranu widać, że mamy łącznie około 3 GB przeznaczone na pamięć podręczną planów, z czego 1,7 GB jest przeznaczone na plany ponad 158 000 zapytań adhoc. Z tego 1,7 GB około 500 MB jest wykorzystywane na 125 000 planów, które wykonują JEDEN tylko czas. Około 1 GB pamięci podręcznej planów jest przeznaczone dla planów przygotowanych i procedur, a zajmują one tylko około 300 MB miejsca. Ale zwróć uwagę na średnią liczbę zastosowań – znacznie ponad 1 milion w przypadku procedur. Patrząc na te dane wyjściowe, sklasyfikowałbym to obciążenie jako mieszane – niektóre sparametryzowane zapytania, niektóre adhoc.
Post na blogu Kimberly omawia opcje zarządzania pamięcią podręczną planów wypełnioną wieloma zapytaniami adhoc. Planowe rozładowanie pamięci podręcznej to tylko jeden problem, z którym musisz się zmierzyć, gdy masz obciążenie adhoc, a w tym poście chcę zbadać wpływ, jaki może to mieć na procesor w wyniku wszystkich kompilacji, które muszą wystąpić. Gdy zapytanie jest wykonywane w programie SQL Server, przechodzi ono przez kompilację i optymalizację, a z tym procesem wiąże się narzut, który często objawia się kosztem procesora. Gdy plan zapytań znajduje się w pamięci podręcznej, można go ponownie użyć. Zapytania, które są sparametryzowane, mogą w końcu ponownie użyć planu, który jest już w pamięci podręcznej, ponieważ tekst zapytania jest dokładnie taki sam. Gdy zapytanie adhoc zostanie wykonane, ponownie użyje planu w pamięci podręcznej tylko wtedy, gdy ma dokładne ten sam tekst i wartości wejściowe .
Konfiguracja
Na potrzeby naszych testów wygenerujemy losowy ciąg znaków w TSQL i połączymy go z zapytaniem, tak aby każde wykonanie miało inną wartość literału. Zawinąłem to w procedurę składowaną, która wywołuje zapytanie przy użyciu dynamicznego wykonywania ciągu (EXEC @QueryString), więc zachowuje się jak instrukcja adhoc. Wywołanie go z procedury składowanej oznacza, że możemy ją wykonać określoną liczbę razy.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
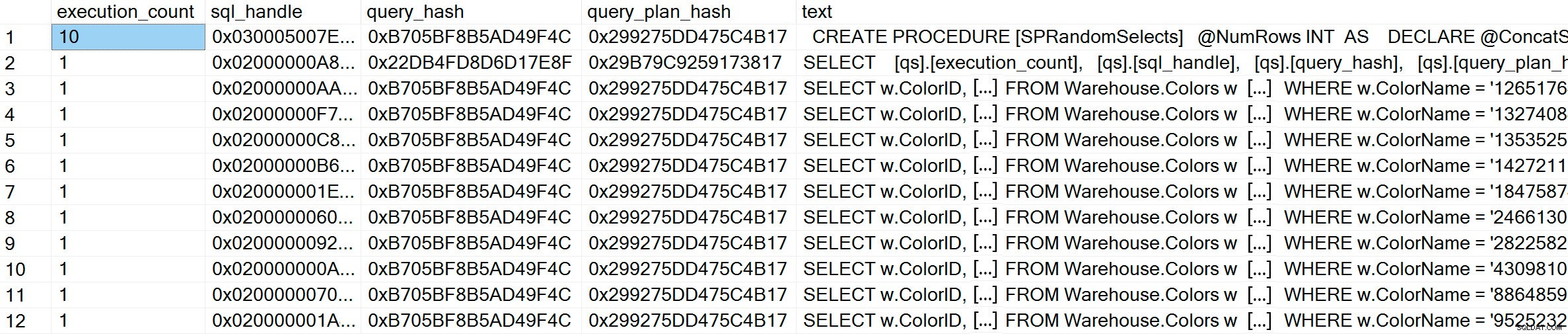
GO Po wykonaniu, jeśli sprawdzimy pamięć podręczną planu, zobaczymy, że mamy 10 unikalnych wpisów, każdy z licznikiem wykonania równym 1 (w razie potrzeby powiększ obraz, aby zobaczyć unikalne wartości predykatu):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Teraz tworzymy prawie identyczną procedurę składowaną, która wykonuje to samo zapytanie, ale sparametryzowaną:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO W pamięci podręcznej planu, oprócz 10 zapytań adhoc, widzimy jeden wpis dla sparametryzowanego zapytania, które zostało wykonane 10 razy. Ponieważ dane wejściowe są sparametryzowane, nawet jeśli do parametru przekazywane są bardzo różne ciągi, tekst zapytania jest dokładnie taki sam:
Testowanie
Teraz, gdy rozumiemy, co dzieje się w pamięci podręcznej planu, stwórzmy więcej obciążenia. Użyjemy pliku wiersza poleceń, który wywołuje ten sam plik .sql w 10 różnych wątkach, przy czym każdy plik wywołuje procedurę składowaną 10 000 razy. Przed rozpoczęciem wyczyścimy pamięć podręczną planu i przechwycimy całkowity procent procesora i kompilacje SQL na sekundę za pomocą PerfMon podczas wykonywania skryptów.
Zawartość pliku Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Zawartość pliku sparametryzowanego.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Przykładowy plik poleceń (oglądany w Notatniku), który wywołuje plik .sql:
Przykładowy plik poleceń (wyświetlany w Notatniku), który tworzy 10 wątków, z których każdy wywołuje plik Run_Adhoc.cmd:
Po uruchomieniu każdego zestawu zapytań w sumie 100 000 razy, jeśli spojrzymy na pamięć podręczną planu, zobaczymy:

W pamięci podręcznej planów znajduje się ponad 10 000 planów adhoc. Możesz się zastanawiać, dlaczego nie ma planu dla wszystkich 100 000 wykonanych zapytań adhoc i ma to związek z działaniem pamięci podręcznej planów (jej rozmiar zależy od dostępnej pamięci, kiedy nieużywane plany są przestarzałe itp.). Najważniejsze jest to, że tak istnieje wiele planów adhoc, w porównaniu z tym, co widzimy dla pozostałych typów pamięci podręcznej.
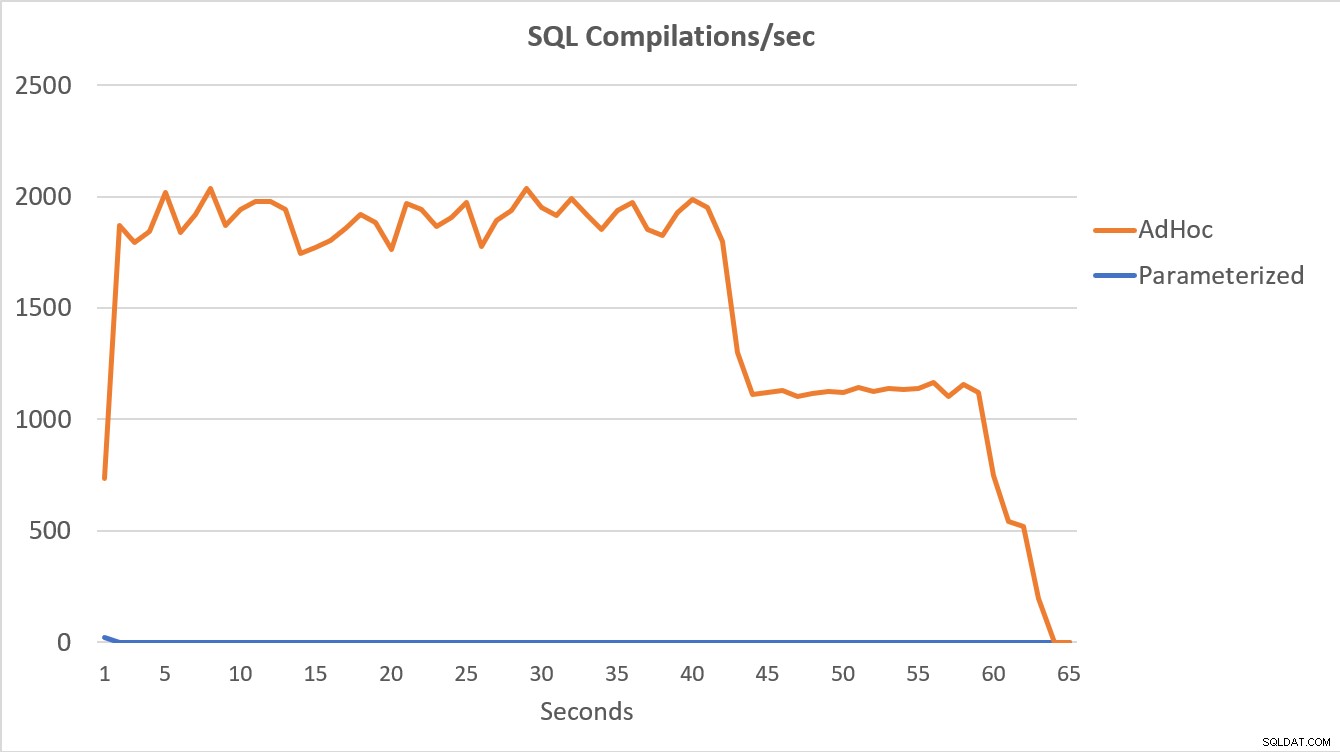
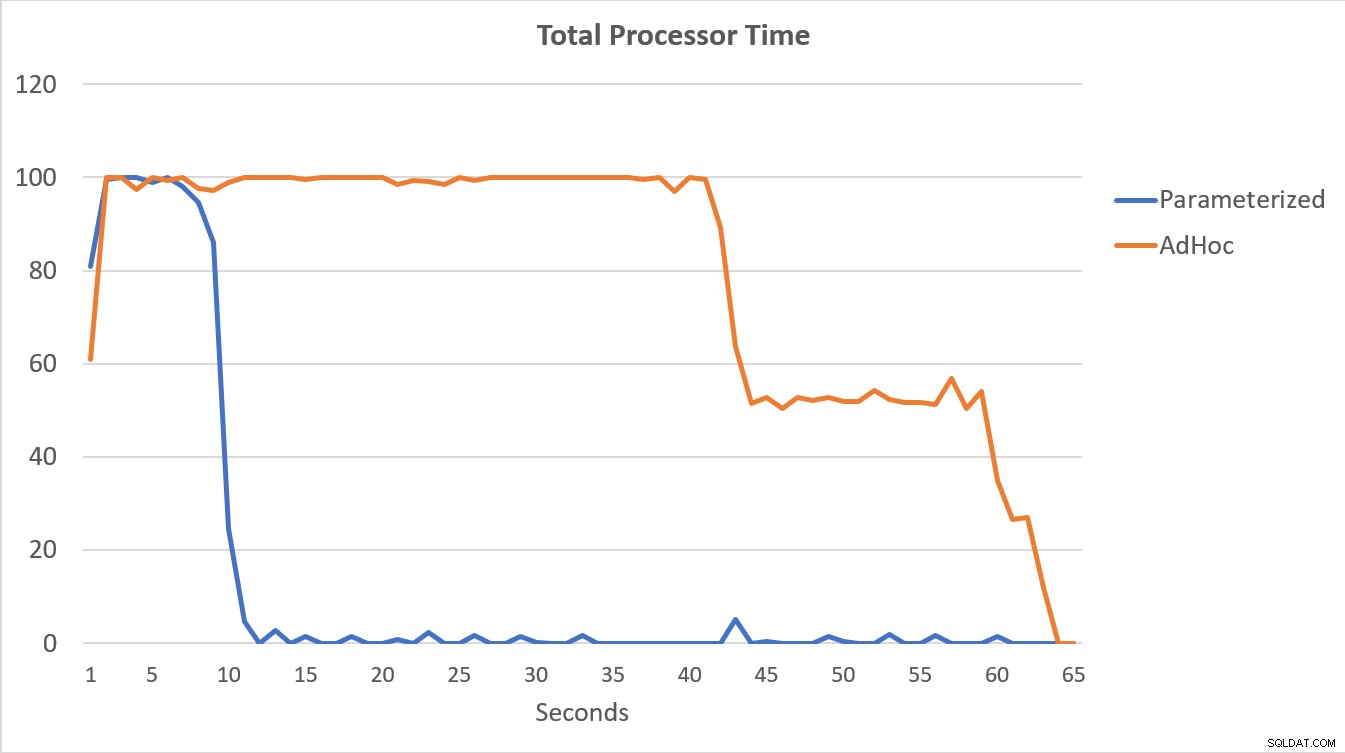
Najbardziej wymowne są dane PerfMon, przedstawione na poniższym wykresie. Wykonanie 100 000 sparametryzowanych zapytań zakończyło się w czasie krótszym niż 15 sekund, a na początku wystąpił niewielki wzrost liczby kompilacji na sekundę, który jest ledwo zauważalny na wykresie. Ta sama liczba wykonań adhoc zajęła nieco ponad 60 sekund, przy czym liczba kompilacji na sekundę wzrosła blisko 2000, po czym spadła do 1000 w okolicach 45 sekund, przy czym przez większość czasu procesor był bliski lub na 100%.
Podsumowanie
Nasz test był niezwykle prosty, ponieważ przesłaliśmy tylko odmiany dla jednej zapytania adhoc, podczas gdy w środowisku produkcyjnym możemy mieć setki lub tysiące różnych odmian dla setek lub tysięcy różnych zapytań ad hoc. Wpływ na wydajność tych zapytań adhoc to nie tylko rozrost pamięci podręcznej planu, który występuje, chociaż spójrz na pamięć podręczną planu to świetne miejsce na rozpoczęcie, jeśli nie znasz rodzaju obciążenia, które masz. Duża liczba zapytań adhoc może napędzać kompilacje, a tym samym procesor, co czasami może być maskowane przez dodanie większej ilości sprzętu, ale może się zdarzyć, że procesor stanie się wąskim gardłem. Jeśli uważasz, że może to być problem lub potencjalny problem w Twoim środowisku, sprawdź, które zapytania adhoc są uruchamiane najczęściej, i zobacz, jakie masz opcje ich parametryzacji. Nie zrozum mnie źle – są potencjalne problemy ze sparametryzowanymi zapytaniami (np. stabilność planu z powodu przekrzywienia danych) i to kolejny problem, z którym być może będziesz musiał się uporać. Niezależnie od obciążenia pracą, ważne jest, aby zrozumieć, że rzadko istnieje metoda „ustaw i zapomnij” w zakresie kodowania, konfiguracji, konserwacji itp. Rozwiązania SQL Server są żywymi, oddychającymi jednostkami, które ciągle się zmieniają i stale dbają i karmią działać niezawodnie. Jednym z zadań administratora baz danych jest bycie na bieżąco z tą zmianą i jak najlepsze zarządzanie wydajnością – niezależnie od tego, czy jest to związane z doraźnymi, czy sparametryzowanymi wyzwaniami dotyczącymi wydajności.