W zeszłym miesiącu opublikowałem wyzwanie stworzenia wydajnego generatora szeregów liczbowych. Odpowiedzi były przytłaczające. Pojawiło się wiele genialnych pomysłów i sugestii o wielu zastosowaniach wykraczających poza to konkretne wyzwanie. Uświadomiłem sobie, jak wspaniale jest być częścią społeczności i jak niesamowite rzeczy można osiągnąć, gdy grupa inteligentnych ludzi połączy siły. Dziękuję Alanowi Bursteinowi, Joe Obbishowi, Adamowi Machanicowi, Christopherowi Fordowi, Jeffowi Modenowi, Charliemu, NoamGrowi, Kamilowi Kosno, Dave Masonowi i Johnowi Number2 za podzielenie się swoimi pomysłami i komentarzami.
Początkowo myślałem o napisaniu tylko jednego artykułu podsumowującego pomysły zgłaszane przez ludzi, ale było ich zbyt wiele. Podzielę więc relację na kilka artykułów. W tym miesiącu skupię się głównie na sugerowanych przez Charliego i Alana Bursteinach ulepszeniach dwóch oryginalnych rozwiązań, które opublikowałem w zeszłym miesiącu w postaci wbudowanych plików TVF o nazwie dbo.GetNumsItzikBatch i dbo.GetNumsItzik. Ulepszone wersje nazwę odpowiednio dbo.GetNumsAlanCharlieItzikBatch i dbo.GetNumsAlanCharlieItzik.
To takie ekscytujące!
Oryginalne rozwiązania Itzika
Dla przypomnienia funkcje, które omówiłem w zeszłym miesiącu, wykorzystują bazowe CTE, które definiuje konstruktor wartości tabeli z 16 wierszami. Funkcje wykorzystują serię kaskadowych CTE, z których każdy stosuje iloczyn (połączenia krzyżowe) dwóch wystąpień poprzedzającego go CTE. W ten sposób, przy pięciu CTE poza podstawowym, można uzyskać zestaw do 4 294 967 296 wierszy. CTE o nazwie Nums używa funkcji ROW_NUMBER do utworzenia serii liczb zaczynających się od 1. Na koniec zewnętrzne zapytanie oblicza liczby w żądanym zakresie między danymi wejściowymi @low i @high.
Funkcja dbo.GetNumsItzikBatch używa fikcyjnego sprzężenia do tabeli z indeksem magazynu kolumn w celu uzyskania przetwarzania wsadowego. Oto kod do utworzenia fikcyjnej tabeli:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A oto kod definiujący funkcję dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Użyłem następującego kodu do przetestowania funkcji z włączoną opcją „Odrzuć wyniki po wykonaniu” w SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki wydajności, które otrzymałem dla tej egzekucji:
CPU time = 16985 ms, elapsed time = 18348 ms.
Funkcja dbo.GetNumsItzik jest podobna, tylko że nie ma sprzężenia fikcyjnego i normalnie przetwarza w trybie wierszowym w całym planie. Oto definicja funkcji:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Oto kod, którego użyłem do testowania funkcji:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki wydajności, które otrzymałem dla tej egzekucji:
CPU time = 19969 ms, elapsed time = 21229 ms.
Ulepszenia Alana Bursteina i Charliego
Alan i Charlie zasugerowali kilka ulepszeń moich funkcji, niektóre z umiarkowanymi implikacjami wydajności, a niektóre z bardziej dramatycznymi. Zacznę od ustaleń Charliego dotyczących ogólnych kosztów kompilacji i ciągłego składania. Następnie omówię sugestie Alana, w tym sekwencje oparte na 1 kontra @niskie (wspólne również przez Charliego i Jeffa Modenów), unikanie niepotrzebnego sortowania i obliczanie zakresu liczb w odwrotnej kolejności.
Wyniki czasu kompilacji
Jak zauważył Charlie, generator serii liczb jest często używany do generowania serii z bardzo małą liczbą wierszy. W takich przypadkach czas kompilacji kodu może stać się istotną częścią całkowitego czasu przetwarzania zapytania. Jest to szczególnie ważne w przypadku korzystania z funkcji iTVF, ponieważ w przeciwieństwie do procedur składowanych to nie sparametryzowany kod zapytania jest optymalizowany, a kod zapytania po osadzeniu parametrów. Innymi słowy, parametry są zastępowane wartościami wejściowymi sprzed optymalizacji, a kod ze stałymi zostaje zoptymalizowany. Proces ten może mieć zarówno negatywne, jak i pozytywne implikacje. Jedną z negatywnych konsekwencji jest to, że otrzymujesz więcej kompilacji, gdy funkcja jest wywoływana z różnymi wartościami wejściowymi. Z tego powodu czasy kompilacji powinny być zdecydowanie brane pod uwagę — szczególnie, gdy funkcja jest używana bardzo często z małymi zakresami.
Oto czasy kompilacji, które Charlie znalazł dla różnych podstawowych mocy CTE:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Ciekawe, że spośród nich 16 jest optymalnym i że następuje bardzo dramatyczny skok, gdy przechodzisz na wyższy poziom, czyli 256. Przypomnij sobie, że funkcje dbo.GetNumsItzikBacth i dbo.GetNumsItzik używają bazowej kardynalności CTE równej 16 .
Składanie ciągłe
Ciągłe składanie jest często pozytywną implikacją, która w odpowiednich warunkach może być włączona dzięki procesowi osadzania parametrów, którego doświadcza iTVF. Załóżmy na przykład, że funkcja ma wyrażenie @x + 1, gdzie @x jest parametrem wejściowym funkcji. Wywołujesz funkcję z @x =5 jako dane wejściowe. Wyrażenie śródliniowe staje się wtedy 5 + 1, a jeśli kwalifikuje się do stałego składania (więcej o tym w skrócie), wtedy staje się 6. Jeśli to wyrażenie jest częścią bardziej złożonego wyrażenia obejmującego kolumny i jest stosowane do wielu milionów wierszy, może to skutkować nieistotnymi oszczędnościami w cyklach procesora.
Trudne jest to, że SQL Server jest bardzo wybredny w kwestii tego, co należy składać w sposób ciągły, a co nie. Na przykład SQL Server nie stałe fold col1 + 5 + 1, ani nie złoży 5 + col1 + 1. Ale złoży 5 + 1 + col1 do 6 + col1. Wiem. Na przykład, jeśli twoja funkcja zwróciła SELECT @x + kol1 + 1 AS mycol1 FROM dbo.T1, możesz włączyć stałe zwijanie z następującą małą zmianą:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Nie wierzysz mi? Sprawdź plany dla następujących trzech zapytań w bazie danych PerformanceV5 (lub podobnych zapytań z Twoimi danymi) i przekonaj się sam:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Otrzymałem następujące trzy wyrażenia w operatorach obliczeniowych skalarnych odpowiednio dla tych trzech zapytań:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Widzisz, dokąd z tym zmierzam? W moich funkcjach użyłem następującego wyrażenia do zdefiniowania kolumny wyniku n:
@low + rownum - 1 AS n
Charlie zdał sobie sprawę, że dzięki następującej małej zmianie może umożliwić ciągłe składanie:
@low - 1 + rownum AS n
Na przykład plan dla wcześniejszego zapytania, który dostarczyłem dla dbo.GetNumsItzik, z @low =1, pierwotnie miał następujące wyrażenie zdefiniowane przez operator Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Po zastosowaniu powyższej drobnej zmiany wyrażenie w planie staje się:
[Expr1154] = Scalar Operator((0)+[Expr1153])
To genialne!
Jeśli chodzi o wpływ na wydajność, pamiętaj, że statystyki wydajności, które otrzymałem dla zapytania przeciwko dbo.GetNumsItzikBatch przed zmianą, były następujące:
CPU time = 16985 ms, elapsed time = 18348 ms.
Oto liczby, które otrzymałem po zmianie:
CPU time = 16375 ms, elapsed time = 17932 ms.
Oto liczby, które otrzymałem dla zapytania skierowanego do dbo.GetNumsItzik pierwotnie:
CPU time = 19969 ms, elapsed time = 21229 ms.
A oto liczby po zmianie:
CPU time = 19266 ms, elapsed time = 20588 ms.
Wydajność poprawiła się tylko o kilka procent. Ale czekaj, jest więcej! Jeśli musisz przetworzyć zamówione dane, wpływ na wydajność może być znacznie bardziej dramatyczny, o czym zajmę się później w sekcji dotyczącej zamawiania.
1 kontra sekwencja @niska i przeciwne numery wierszy
Alan, Charlie i Jeff zauważyli, że w zdecydowanej większości rzeczywistych przypadków, w których potrzebny jest zakres liczb, musi on zaczynać się od 1, a czasem od 0. O wiele rzadziej potrzebny jest inny punkt początkowy. Dlatego bardziej sensowne może być, aby funkcja zawsze zwracała zakres, który zaczyna się od, powiedzmy, 1, a gdy potrzebujesz innego punktu początkowego, zastosuj wszelkie obliczenia zewnętrznie w zapytaniu względem funkcji.
Alan wpadł na elegancki pomysł, aby wbudowany TVF zwracał zarówno kolumnę, która zaczyna się od 1 (po prostu bezpośredni wynik funkcji ROW_NUMBER) aliasowaną jako rn, jak i kolumnę, która zaczyna się od @low aliasowana jako n. Ponieważ funkcja jest wbudowana, gdy zewnętrzne zapytanie oddziałuje tylko z kolumną rn, kolumna n nie jest nawet oceniana i uzyskujesz korzyści związane z wydajnością. Jeśli potrzebujesz, aby sekwencja zaczynała się od @low, wchodzisz w interakcję z kolumną n i płacisz stosowny dodatkowy koszt, więc nie ma potrzeby dodawania żadnych jawnych obliczeń zewnętrznych. Alan zasugerował nawet dodanie kolumny o nazwie op, która oblicza liczby w odwrotnej kolejności i wchodzi z nią w interakcję tylko wtedy, gdy zachodzi taka potrzeba. Kolumna op opiera się na wyliczeniu:@high + 1 – rownum. Ta kolumna ma znaczenie, gdy musisz przetworzyć wiersze w malejącej kolejności według numerów, co zademonstruję w dalszej części rozdziału o kolejności.
Zastosujmy więc ulepszenia Charliego i Alana do moich funkcji.
W przypadku wersji w trybie wsadowym najpierw utwórz fikcyjną tabelę z indeksem magazynu kolumn, jeśli jeszcze go nie ma:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Następnie użyj następującej definicji dla funkcji dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Oto przykład użycia funkcji:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Ten kod generuje następujące dane wyjściowe:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Następnie przetestuj wydajność funkcji za pomocą 100 mln wierszy, najpierw zwracając kolumnę n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki wydajności, które uzyskałem dla tego wykonania:
CPU time = 16375 ms, elapsed time = 17932 ms.
Jak widać, jest niewielka poprawa w porównaniu z dbo.GetNumsItzikBatch zarówno pod względem procesora, jak i upływającego czasu, dzięki ciągłemu składaniu, które miało tutaj miejsce.
Przetestuj funkcję, tylko tym razem zwracając kolumnę rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki wydajności, które uzyskałem dla tego wykonania:
CPU time = 15890 ms, elapsed time = 18561 ms.
Czas procesora uległ dalszemu skróceniu, chociaż wydaje się, że czas, który upłynął, nieco się wydłużył w tym wykonaniu w porównaniu z zapytaniem o kolumnę n.
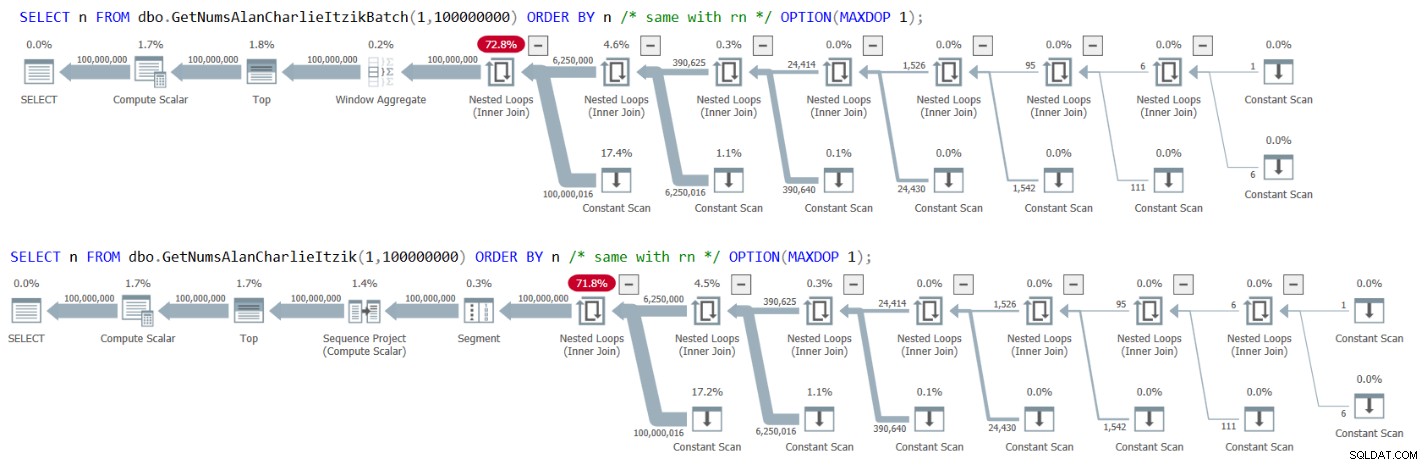
Rysunek 1 przedstawia plany dla obu zapytań.
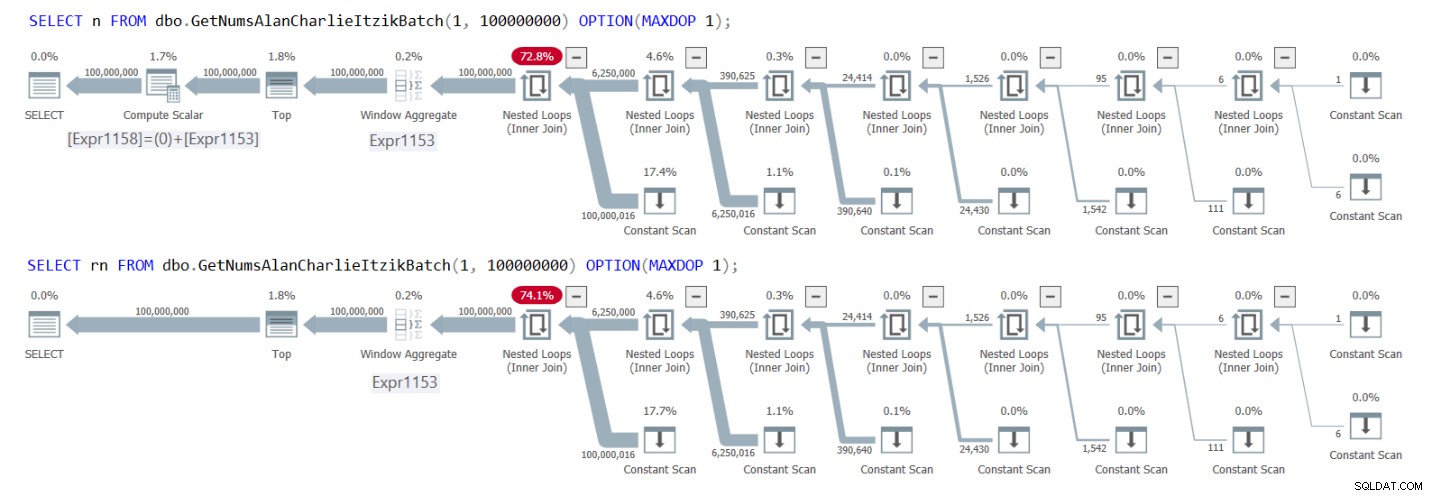 Rysunek 1:Plany GetNumsAlanCharlieItzikBatch zwracające n kontra rn
Rysunek 1:Plany GetNumsAlanCharlieItzikBatch zwracające n kontra rn
W planach wyraźnie widać, że podczas interakcji z kolumną rn nie ma potrzeby stosowania dodatkowego operatora Compute Scalar. Zwróć także uwagę na pierwszy plan wynik ciągłej czynności składania, którą opisałem wcześniej, gdzie @low – 1 + rownum zostało wstawione do 1 – 1 + rownum, a następnie złożone do 0 + rownum.
Oto definicja wersji funkcji w trybie wierszowym o nazwie dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Użyj następującego kodu, aby przetestować funkcję, najpierw odpytując kolumnę n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki wydajności, które otrzymałem:
CPU time = 19047 ms, elapsed time = 20121 ms.
Jak widać, jest nieco szybszy niż dbo.GetNumsItzik.
Następnie zapytaj kolumnę rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Dane dotyczące wydajności dodatkowo poprawiają się zarówno pod względem procesora, jak i upływu czasu:
CPU time = 17656 ms, elapsed time = 18990 ms.
Uwagi dotyczące zamawiania
Wspomniane wyżej ulepszenia są z pewnością interesujące, a wpływ na wydajność jest znikomy, ale niezbyt znaczący. O wiele bardziej dramatyczny i głęboki wpływ na wydajność można zaobserwować, gdy trzeba przetworzyć dane uporządkowane według kolumny liczb. Może to być tak proste, jak konieczność zwrócenia uporządkowanych wierszy, ale jest tak samo istotne w przypadku każdej potrzeby przetwarzania opartego na zamówieniach, np. operatora Stream Aggregate do grupowania i agregacji, algorytmu Merge Join do łączenia i tak dalej.
Podczas wykonywania zapytania dbo.GetNumsItzikBatch lub dbo.GetNumsItzik i porządkowania według n, optymalizator nie zdaje sobie sprawy, że podstawowe wyrażenie porządkujące @low + rownum – 1 jest zachowujące kolejność w odniesieniu do rownum. Implikacja jest nieco podobna do wyrażenia filtrującego niepodlegającego SARG, tylko z wyrażeniem porządkującym skutkuje to jawnym operatorem sortowania w planie. Dodatkowe sortowanie wpływa na czas odpowiedzi. Wpływa również na skalowanie, które zwykle zmienia się w n log n zamiast n.
Aby to zademonstrować, wykonaj zapytanie dbo.GetNumsItzikBatch, żądając kolumny n, uporządkowanej według n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Mam następujące statystyki wydajności:
CPU time = 34125 ms, elapsed time = 39656 ms.
Czas działania jest ponad dwukrotnie większy w porównaniu z testem bez klauzuli ORDER BY.
Przetestuj funkcję dbo.GetNumsItzik w podobny sposób:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Do tego testu otrzymałem następujące liczby:
CPU time = 52391 ms, elapsed time = 55175 ms.
Również tutaj czas działania jest ponad dwukrotnie większy w porównaniu z testem bez klauzuli ORDER BY.
Rysunek 2 przedstawia plany dla obu zapytań.
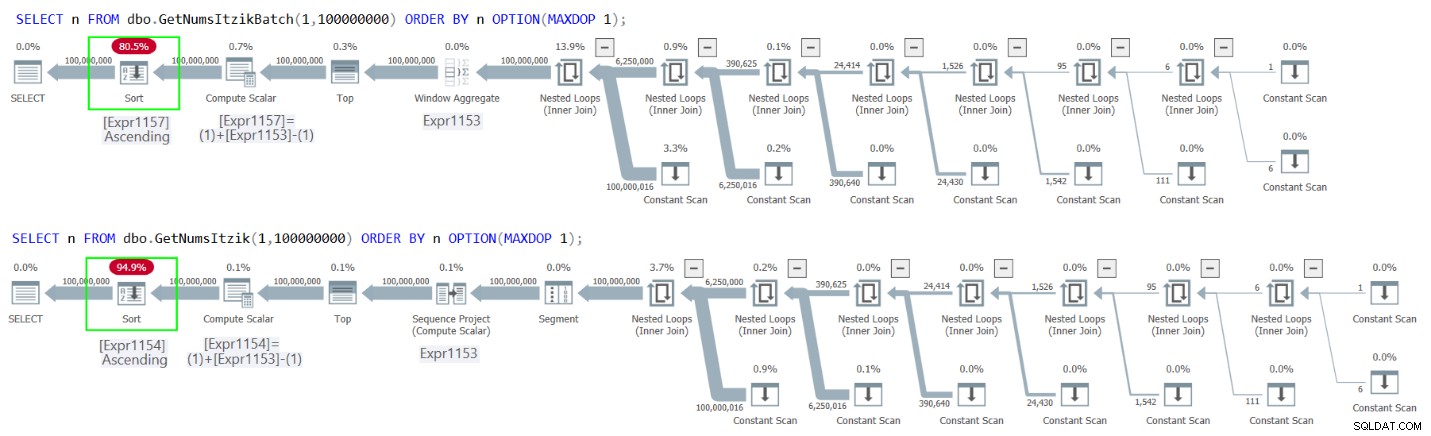 Rysunek 2:Plany zamawiania GetNumsItzikBatch i GetNumsItzik według n
Rysunek 2:Plany zamawiania GetNumsItzikBatch i GetNumsItzik według n
W obu przypadkach możesz zobaczyć wyraźny operator sortowania w planach.
Podczas wykonywania zapytania dbo.GetNumsAlanCharlieItzikBatch lub dbo.GetNumsAlanCharlieItzik i zamawiania przez rn optymalizator nie musi dodawać operatora Sort do planu. Więc możesz zwrócić n, ale uporządkuj według rn iw ten sposób unikniesz sortowania. Co jest jednak nieco szokujące – i mam to na myśli w dobrym tego słowa znaczeniu – to to, że poprawiona wersja n, która podlega ciągłemu składaniu, zachowuje porządek! Optymalizator może łatwo zorientować się, że 0 + rownum jest wyrażeniem zachowującym porządek w odniesieniu do rownum, dzięki czemu unika się sortowania.
Spróbuj. Zapytanie dbo.GetNumsAlanCharlieItzikBatch, zwrócenie n i uporządkowanie według n lub rn, na przykład:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Otrzymałem następujące wyniki:
CPU time = 16500 ms, elapsed time = 17684 ms.
Dzieje się tak oczywiście dzięki temu, że w planie nie było potrzeby stosowania operatora sortowania.
Uruchom podobny test na dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Otrzymałem następujące numery:
CPU time = 19546 ms, elapsed time = 20803 ms.
Rysunek 3 przedstawia plany dla obu zapytań:
Rysunek 3:Plany GetNumsAlanCharlieItzikBatch i GetNumsAlanCharlieItzik według n lub rn
Zauważ, że w planach nie ma operatora sortowania.
Sprawia, że chcesz śpiewać…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Dziękuję Charlie!
Ale co, jeśli musisz zwrócić lub przetworzyć liczby w kolejności malejącej? Oczywistą próbą jest użycie ORDER BY n DESC lub ORDER BY rn DESC, na przykład:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Niestety, oba przypadki skutkują wyraźnym sortowaniem planów, jak pokazano na rysunku 4.
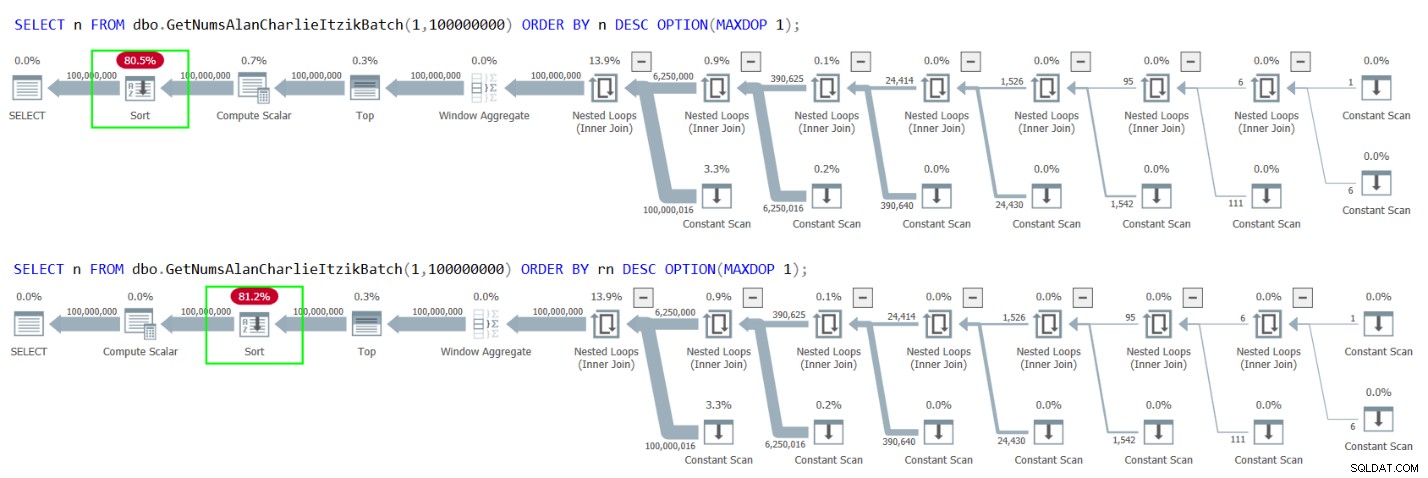 Rysunek 4:Plany GetNumsAlanCharlieItzikBatch sortowanie według n lub rn malejąco
Rysunek 4:Plany GetNumsAlanCharlieItzikBatch sortowanie według n lub rn malejąco
W tym miejscu sprytna sztuczka Alana z operacją kolumny ratuje życie. Zwróć kolumnę op podczas porządkowania według n lub rn, tak jak poniżej:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Plan dla tego zapytania pokazano na rysunku 5.
 Rysunek 5:Plan GetNumsAlanCharlieItzikBatch zwracający op i porządkujący według n lub rn rosnąco
Rysunek 5:Plan GetNumsAlanCharlieItzikBatch zwracający op i porządkujący według n lub rn rosnąco
Otrzymujesz dane uporządkowane n malejąco i nie ma potrzeby sortowania w planie.
Dziękuję Alan!
Podsumowanie wyników
Więc czego nauczyliśmy się z tego wszystkiego?
Czasy kompilacji mogą mieć znaczenie, szczególnie w przypadku częstego korzystania z funkcji z małymi zakresami. W skali logarytmicznej o podstawie 2, słodka 16 wydaje się być ładną magiczną liczbą.
Poznaj specyfikę ciągłego składania i wykorzystaj je na swoją korzyść. Gdy iTVF zawiera wyrażenia, które zawierają parametry, stałe i kolumny, umieść parametry i stałe w wiodącej części wyrażenia. Zwiększy to prawdopodobieństwo złożenia, zmniejszy obciążenie procesora i zwiększy prawdopodobieństwo zachowania porządku.
Dobrze jest mieć wiele kolumn, które są używane do różnych celów w iTVF i za każdym razem sprawdzać odpowiednie kolumny, nie martwiąc się o płacenie za te, do których nie ma odniesienia.
Gdy potrzebujesz sekwencji liczb zwróconej w odwrotnej kolejności, użyj oryginalnej kolumny n lub rn w klauzuli ORDER BY w kolejności rosnącej i zwróć kolumnę op, która oblicza liczby w kolejności odwrotnej.
Rysunek 6 podsumowuje wyniki, które uzyskałem w różnych testach.
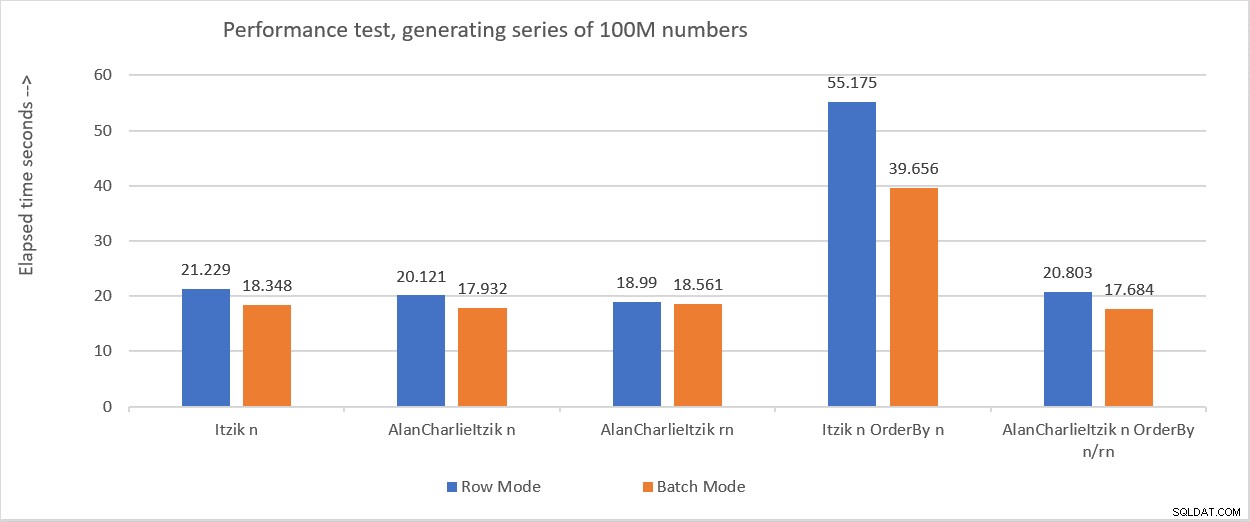 Rysunek 6:Podsumowanie skuteczności
Rysunek 6:Podsumowanie skuteczności
W przyszłym miesiącu będę kontynuować odkrywanie dodatkowych pomysłów, spostrzeżeń i rozwiązań wyzwania generatora serii liczb.