Uwaga:fragmenty bloga zawierają odniesienia i przykłady z „ANNOUNCING AVAILABILITY OF POSTGRERSQL INSTANCE LEVEL ENCRYPTION” autorstwa CyberTec, firmy zapewniającej wsparcie, doradztwo i szkolenia dotyczące PostgreSQL.
Organizacje mają do czynienia z różnymi rodzajami danych, w tym z bardzo istotnymi informacjami, które muszą być przechowywane w bazie danych. Bezpieczeństwo jest kluczowym aspektem, który należy wziąć pod uwagę, aby zapewnić, że dane wrażliwe, takie jak dokumentacja medyczna i transakcje finansowe, nie trafią w ręce osób korzystających z niegodziwych środków. Przez lata programiści wymyślali wiele sposobów poprawy integralności i ochrony danych. Jedną z najczęściej stosowanych technik jest szyfrowanie w celu zapobiegania naruszeniom danych.
Chociaż mogłeś użyć złożonych środków ochrony, niektóre osoby mogą nadal uzyskiwać dostęp do Twojego systemu. Szyfrowanie to dodatkowa warstwa bezpieczeństwa. PostgreSQL oferuje szyfrowanie na różnych poziomach, poza zapewnieniem elastyczności w ochronie danych przed ujawnieniem w wyniku nierzetelnych administratorów, niezabezpieczonych połączeń sieciowych i kradzieży serwerów baz danych. PostgreSQL zapewnia różne opcje szyfrowania, takie jak:
- Uwierzytelnianie hosta SSL
- Szyfrowanie danych w sieci
- Szyfrowanie partycji danych
- Szyfrowanie określonych kolumn
- Szyfrowanie przechowywania haseł
- Szyfrowanie po stronie klienta
Jednak im bardziej wyrafinowana strategia szyfrowania zostanie zastosowana, tym większe prawdopodobieństwo, że zostaniesz zablokowany przed dostępem do swoich danych. Poza tym proces czytania będzie nie tylko trudny, ale także wymaga dużej ilości zasobów do odpytywania i odszyfrowywania. Wybrana opcja szyfrowania zależy od charakteru danych, z którymi masz do czynienia pod względem wrażliwości. Poniższy diagram ilustruje ogólną procedurę szyfrowania i deszyfrowania danych podczas transakcji na serwerze.
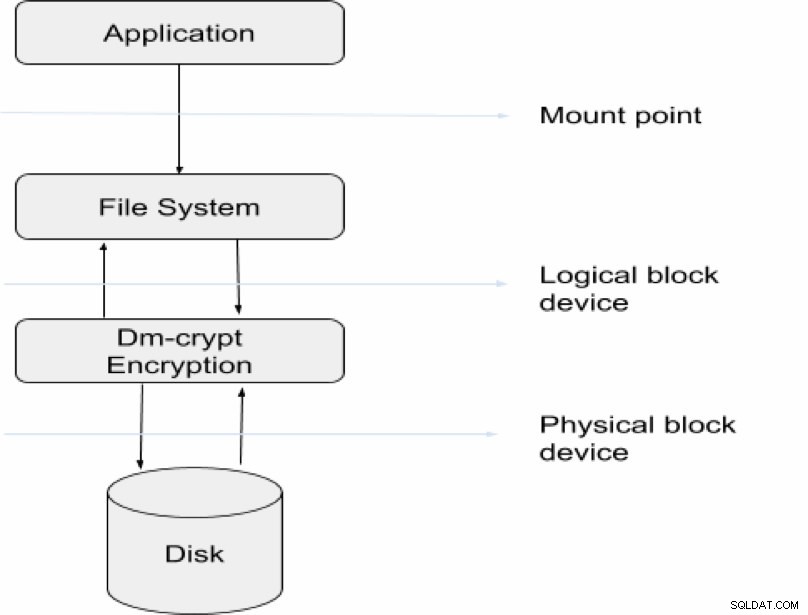
W tym artykule omówiono różne sposoby, w jakie przedsiębiorstwo może zabezpieczyć poufne informacje, ale głównym punktem zainteresowania będzie wspomniane wcześniej szyfrowanie na poziomie instancji.
Szyfrowanie
Szyfrowanie to praktyka kodowania danych w taki sposób, że nie są już w swoim oryginalnym formacie i nie można ich odczytać. W odniesieniu do bazy danych istnieją 2 rodzaje danych:dane w spoczynku i dane w ruchu. Gdy dane są przechowywane w bazie danych, określa się je jako dane w spoczynku. Z drugiej strony, jeśli klient np. wyśle żądanie do bazy danych, jeśli jakieś dane zostaną zwrócone i muszą dotrzeć do klienta, to jest to określane jako dane w ruchu. Te dwa różne typy danych muszą być chronione przy użyciu podobnej technologii. Na przykład, jeśli aplikacja została opracowana w taki sposób, że użytkownik musi podać hasło, to hasło nie zostanie zapisane w bazie danych jako zwykły tekst. Istnieje kilka procedur kodowania, które służą do zmiany tego zwykłego tekstu na inny ciąg przed zapisaniem. Poza tym, jeśli użytkownik musi użyć tego hasła na przykład do systemu logowania, potrzebujemy sposobu na porównanie tego, który zostanie przesłany w procesie deszyfrowania.
Szyfrowanie bazy danych można zaimplementować na różne sposoby, ale wielu programistów nie bierze pod uwagę poziomu transportu. Jednak różne podejścia wiążą się również z różnymi pułapkami związanymi ze spowolnionym czasem dostępu do danych, zwłaszcza gdy pamięć wirtualna jest intensywnie wykorzystywana.
Szyfrowanie danych w spoczynku
Dane w spoczynku oznaczają nieaktywne dane, które są fizycznie przechowywane na dysku. Jeśli chodzi o hosting bazy danych w środowisku chmury, gdzie dostawca chmury ma pełny dostęp do infrastruktury, szyfrowanie może być dobrym sposobem na zachowanie kontroli nad danymi. Niektóre strategie szyfrowania, których możesz użyć, zostały omówione poniżej.
Pełne szyfrowanie dysku (FDE)
Koncepcja FDE polega na ogół na ochronie każdego pliku i tymczasowego magazynu, który może zawierać części danych. Jest to dość wydajne, zwłaszcza gdy masz trudności z wybraniem tego, co chcesz chronić, a raczej jeśli nie chcesz przegapić pliku. Główną zaletą tej strategii jest to, że nie wymaga szczególnej uwagi ze strony użytkownika końcowego po uzyskaniu dostępu do systemu. Takie podejście ma jednak pewne pułapki. Należą do nich:
- Proces szyfrowania i odszyfrowywania spowalnia ogólny czas dostępu do danych.
- Dane mogą nie być chronione, gdy system jest włączony, ponieważ informacje zostaną odszyfrowane i gotowe do odczytu. Dlatego musisz zastosować inne strategie szyfrowania, takie jak szyfrowanie oparte na plikach.
Szyfrowanie oparte na plikach
W takim przypadku pliki lub katalogi są szyfrowane przez sam kryptograficzny system plików z możliwością układania w stos. W PostgreSQL często używamy podejścia pg_crypto, jak omówiono w tym artykule.
Niektóre z zalet szyfrowania systemu plików to:
- Kontrolę akcji można wymusić za pomocą kryptografii klucza publicznego
- Oddzielne zarządzanie zaszyfrowanymi plikami, takie jak tworzenie kopii zapasowych indywidualnie zmienionych plików, nawet w postaci zaszyfrowanej, zamiast tworzenia kopii zapasowej całego zaszyfrowanego woluminu.
Jednak nie jest to zbyt niezawodna metoda szyfrowania, której można użyć do danych klastrowanych. Powodem jest to, że niektóre rozwiązania do szyfrowania oparte na plikach mogą pozostawić resztki zaszyfrowanych plików, z których atakujący może się odzyskać. Najlepszym podejściem do kombinacji jest zatem połączenie tego z pełnym szyfrowaniem dysku.
Szyfrowanie na poziomie instancji
Poziom instancji używa buforów, dzięki czemu wszystkie pliki tworzące klaster PostgreSQL są przechowywane na dysku jako szyfrowanie danych w spoczynku. Są one następnie prezentowane jako bloki deszyfrowania, gdy są odczytywane z dysku do współdzielonych buforów. Po zapisaniu tych bloków na dysk ze współdzielonych buforów są one ponownie szyfrowane automatycznie. Baza danych jest najpierw inicjowana z szyfrowaniem za pomocą polecenia initdb. Po drugie, podczas uruchamiania klucz szyfrowania jest pobierany przez serwer na jeden z tych dwóch sposobów; poprzez parametr pgcrypto.keysetup_command lub przez zmienną środowiskową.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentKonfigurowanie szyfrowania na poziomie instancji
Krótkie podsumowanie tego, jak skonfigurować szyfrowanie na poziomie instancji, przedstawiono w poniższych krokach:
- Sprawdź, czy masz zainstalowany „contrib” za pomocą polecenia rpm -qa |grep contrib dla systemu operacyjnego opartego na RedHat lub dpkg -l |grep contrib dla systemu operacyjnego opartego na Debianie. Jeśli nie ma go na liście, zainstaluj go za pomocą apt-get install postgresql-contrib, jeśli używasz środowiska opartego na Debianie lub yum install postgresql-contrib, jeśli używasz systemu operacyjnego opartego na RedHat.
- Zbuduj kod PostgreSQL.
- Inicjowanie klastra przez ustanowienie klucza szyfrowania i uruchomienie polecenia he initdb
read -sp "Postgres passphrase: " PGENCRYPTIONKEY export PGENCRYPTIONKEY=$PGENCRYPTIONKEY initdb –data-encryption pgcrypto --data-checksums -D cryptotest - Uruchom serwer poleceniem
$ postgres -D /usr/local/pgsql/data - Ustawianie zmiennej środowiskowej PGENCRYPTIONKEY za pomocą polecenia:
Klucz można również ustawić za pomocą niestandardowej i bezpieczniejszej procedury odczytu klucza za pomocą wspomnianego powyżej parametru postgresql.conf „pgcrypto.keysetup_command”.export PGENCRYPTIONKEY=topsecret pg_ctl -D cryptotest start
Oczekiwania dotyczące wydajności
Szyfrowanie zawsze odbywa się kosztem wydajności, ponieważ nie ma opcji bez kosztów. Jeśli Twoje obciążenie jest zorientowane na operacje we/wy, możesz spodziewać się znacznie zmniejszonej wydajności, ale może tak nie być. Czasami na typowym sprzęcie serwerowym, jeśli zestaw danych jest mniej współdzielony w buforach lub jego czas przebywania w buforach jest krótki, spadek wydajności może być znikomy.
Po zaszyfrowaniu mojej bazy danych przeprowadziłem mały test, aby sprawdzić, czy szyfrowanie naprawdę wpływa na wydajność, a wyniki przedstawiono poniżej.
| Obciążenie | Brak szyfrowania | Z szyfrowaniem | Koszt wydajności |
|---|---|---|---|
| Operacja wstawiania zbiorczego | 26s | 68 lat | 161% |
| Dopasowanie odczytu i zapisu do wspólnych buforów (w stosunku 1:3) | 3200TPS | 3068TPS | 4.13% |
| Odczyt tylko ze współdzielonych buforów | 2234 TPS | 2219 TPS | 0,68% |
| Tylko do odczytu nie mieści się w udostępnionych buforach | 1845 TP | 1434 TPS | 22,28% |
| Odczyt-zapis nie mieści się we wspólnych buforach w stosunku 1:3 | 3422 TPS | 2545 TPS | 25,6% |
Jak pokazano w powyższej tabeli, widzimy, że wydajność jest nieliniowa, ponieważ czasami przeskakuje z 161% do 0,7%. Jest to prosta wskazówka, że wydajność szyfrowania jest zależna od obciążenia, poza tym, że jest wrażliwa na ilość stron przenoszonych między współdzielonymi buforami a dyskiem. Może to również wpływać na moc procesora w zależności od obciążenia. Szyfrowanie na poziomie instancji jest całkiem realną opcją i najprostszym podejściem w wielu środowiskach.
Wniosek
Szyfrowanie danych jest ważnym przedsięwzięciem, szczególnie w przypadku poufnych informacji w zarządzaniu bazami danych. W przypadku PostgreSQL dostępnych jest wiele opcji szyfrowania danych. Przy określaniu, które podejście należy zastosować, ważne jest zrozumienie danych, architektury aplikacji i wykorzystania danych, ponieważ szyfrowanie odbywa się kosztem wydajności. W ten sposób będziesz w stanie zrozumieć:kiedy włączyć szyfrowanie, gdzie są narażone Twoje dane i gdzie są bezpieczne, co jest najlepszą metodą szyfrowania.