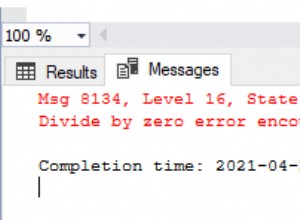
Jeśli niczego nie przegapiłem:
WITH ranked AS (
SELECT
ChangeDate,
ColPK,
Col1,
Col2,
Col3,
Col4,
Col5,
OverallRank = ROW_NUMBER() OVER (PARTITION BY ColPK ORDER BY ChangeDate),
Col1Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col1 ORDER BY ChangeDate),
Col2Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col2 ORDER BY ChangeDate),
Col3Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col3 ORDER BY ChangeDate),
Col4Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col4 ORDER BY ChangeDate),
Col5Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col5 ORDER BY ChangeDate)
FROM AuditTable
)
, ranked2 AS (
SELECT
ChangeDate,
ColPK,
Col1,
Col2,
Col3,
Col4,
Col5,
Col1Group = RANK() OVER (PARTITION BY ColPK, Col1 ORDER BY OverallRank - Col1Rank),
Col2Group = RANK() OVER (PARTITION BY ColPK, Col2 ORDER BY OverallRank - Col2Rank),
Col3Group = RANK() OVER (PARTITION BY ColPK, Col3 ORDER BY OverallRank - Col3Rank),
Col4Group = RANK() OVER (PARTITION BY ColPK, Col4 ORDER BY OverallRank - Col4Rank),
Col5Group = RANK() OVER (PARTITION BY ColPK, Col5 ORDER BY OverallRank - Col5Rank),
Col1Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col1, OverallRank - Col1Rank ORDER BY ChangeDate),
Col2Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col2, OverallRank - Col2Rank ORDER BY ChangeDate),
Col3Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col3, OverallRank - Col3Rank ORDER BY ChangeDate),
Col4Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col4, OverallRank - Col4Rank ORDER BY ChangeDate),
Col5Rank = ROW_NUMBER() OVER (PARTITION BY ColPK, Col5, OverallRank - Col5Rank ORDER BY ChangeDate)
FROM ranked
),
unpivoted AS (
SELECT
r.ChangeTime,
r.ColPK,
x.ColName,
ColRank = CASE x.Colname
WHEN 'Col1' THEN Col1Group
WHEN 'Col2' THEN Col2Group
WHEN 'Col3' THEN Col3Group
WHEN 'Col4' THEN Col4Group
WHEN 'Col5' THEN Col5Group
END,
Value = CASE x.Colname
WHEN 'Col1' THEN CONVERT(nvarchar(100), r.Col1)
WHEN 'Col2' THEN CONVERT(nvarchar(100), r.Col2)
WHEN 'Col3' THEN CONVERT(nvarchar(100), r.Col3)
WHEN 'Col4' THEN CONVERT(nvarchar(100), r.Col4)
WHEN 'Col5' THEN CONVERT(nvarchar(100), r.Col5)
END
FROM ranked2 r
INNER JOIN (VALUES ('Col1'), ('Col2'), ('Col3'), ('Col4'), ('Col5')) x (ColName)
ON x.ColName = 'Col1' AND Col1Rank = 1
OR x.ColName = 'Col2' AND Col2Rank = 1
OR x.ColName = 'Col3' AND Col3Rank = 1
OR x.ColName = 'Col4' AND Col4Rank = 1
OR x.ColName = 'Col5' AND Col5Rank = 1
)
SELECT
new.ChangeTime,
new.ColPK,
new.ColName,
old.Value AS OldValue,
new.Value AS NewValue
FROM unpivoted new
LEFT JOIN unpivoted old
ON new.ColPK = old.ColPK
AND new.ColName = old.ColName
AND new.ColRank = old.ColRank + 1
Zasadniczo chodzi o uszeregowanie sąsiednich grup identycznych wartości i wybranie pierwszych wystąpień każdej wartości. Odbywa się to dla każdej kolumny, której wartości są poddawane inspekcji, a kolumny nie są przestawne w procesie. Następnie nieobrotowy zestaw wierszy jest łączony ze sobą, tj. dla każdego PK i nazwy kolumny każdy wiersz jest dopasowywany do swojego poprzednika (na podstawie rankingu), aby uzyskać starą wartość w tym samym wierszu dla końcowego zestawu wyników.