Jedną z fajnych funkcji Galera jest automatyczne przydzielanie węzłów i kontrola członkostwa. Jeśli węzeł ulegnie awarii lub utraci komunikację, zostanie automatycznie usunięty z klastra i nie będzie działał. Dopóki większość węzłów nadal się komunikuje (Galera nazywa ten komputer PC - podstawowym komponentem), istnieje bardzo duża szansa, że uszkodzony węzeł będzie mógł automatycznie ponownie dołączyć, ponownie zsynchronizować i wznowić replikację po przywróceniu łączności.
Ogólnie wszystkie węzły Galera są równe. Pełnią ten sam zestaw danych i taką samą rolę jak mastery, mogą jednocześnie obsługiwać odczyt i zapis, dzięki komunikacji grupowej Galera i wtyczce replikacji opartej na certyfikacji. Dlatego w rzeczywistości nie ma przełączania awaryjnego z punktu widzenia bazy danych ze względu na tę równowagę. Tylko od strony aplikacji, która wymagałaby przełączenia awaryjnego, aby pominąć niedziałające węzły podczas partycjonowania klastra.
W tym poście na blogu przyjrzymy się, jak Galera Cluster wykonuje odzyskiwanie węzłów i klastrów w przypadku partycjonowania sieci. Na marginesie, jakiś czas temu omówiliśmy podobny temat w tym poście na blogu. Codership szczegółowo wyjaśnił koncepcję odzyskiwania Galery na stronie dokumentacji, Awaria i odzyskiwanie węzła.
Awaria i eksmisja węzła
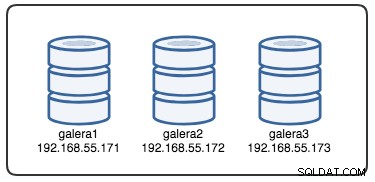
Aby zrozumieć odzyskiwanie, musimy zrozumieć, w jaki sposób Galera najpierw wykrywa awarię węzła i proces eksmisji. Umieśćmy to w kontrolowanym scenariuszu testowym, abyśmy mogli lepiej zrozumieć proces eksmisji. Załóżmy, że mamy trzywęzłowy klaster Galera, jak pokazano poniżej:
Do pobrania opcji dostawcy Galera można użyć następującego polecenia:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GTo długa lista, ale musimy tylko skupić się na niektórych parametrach, aby wyjaśnić proces:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Przede wszystkim Galera stosuje formatowanie ISO 8601, aby reprezentować czas trwania. P1D oznacza, że czas trwania wynosi jeden dzień, natomiast PT15S oznacza czas trwania to 15 sekund (zwróć uwagę na oznaczenie czasu T, które poprzedza wartość czasu). Na przykład, jeśli ktoś chciałby zwiększyć evs.view_forget_timeout na 1 i pół dnia można ustawić P1DT12H lub PT36H.
Biorąc pod uwagę, że wszystkie hosty nie zostały skonfigurowane z żadnymi regułami zapory sieciowej, używamy następującego skryptu o nazwie block_galera.sh na galera2 aby zasymulować awarię sieci do/z tego węzła:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateWykonując skrypt, otrzymujemy następujące dane wyjściowe:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Zgłoszony znacznik czasu można uznać za początek partycjonowania klastra, w którym tracimy galera2, podczas gdy galera1 i galera3 są nadal online i dostępne. W tym momencie nasza architektura klastra Galera wygląda mniej więcej tak:
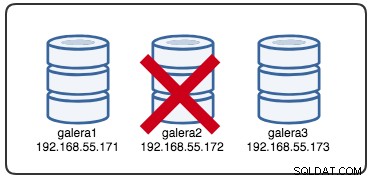
Z perspektywy węzła partycjonowanego
Na galera2 zobaczysz wydruki w dzienniku błędów MySQL. Podzielmy je na kilka części. Przestój rozpoczął się około 16:46:02 czasu UTC i po gmcast.peer_timeout=PT3S , pojawi się następujący komunikat:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Jak minął evs.suspect_timeout =PT5S , oba węzły galera1 i galera3 są podejrzewane jako martwe przez galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveNastępnie Galera zrewiduje bieżący widok klastra i położenie tego węzła:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})W nowym widoku klastra Galera wykona obliczenia kworum, aby zdecydować, czy ten węzeł jest częścią komponentu podstawowego. Jeśli nowy komponent widzi „podstawowy =nie”, Galera zdegraduje stan węzła lokalnego z SYNCED do OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Dzięki najnowszej zmianie w widoku klastra i stanie węzła Galera zwraca widok klastra po eksmisji i stan globalny, jak poniżej:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Możesz zobaczyć, że w tym okresie zmieniły się następujące globalne statusy galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+W tym momencie serwer MySQL/MariaDB na galera2 jest nadal dostępny (baza danych nasłuchuje na 3306, a Galera na 4567) i możesz odpytywać tabele systemowe mysql i wyświetlać listę baz danych i tabel. Jednak gdy wskoczysz do tabel niesystemowych i wykonasz proste zapytanie, takie jak to:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useNatychmiast pojawi się błąd wskazujący, że WSREP jest załadowany, ale nie jest gotowy do użycia przez ten węzeł, zgodnie z raportem wsrep_ready status. Dzieje się tak, ponieważ węzeł traci połączenie z Elementem Podstawowym i przechodzi w stan nieoperacyjny (status węzła lokalnego został zmieniony z SYNCED na OPEN). Dane odczytywane z węzłów w stanie nieoperacyjnym są uważane za przestarzałe, chyba że ustawisz wsrep_dirty_reads=ON aby zezwolić na odczyty, chociaż Galera nadal odrzuca każde polecenie, które modyfikuje lub aktualizuje bazę danych.
Wreszcie Galera będzie nadal słuchać i łączyć się z innymi członkami w tle w nieskończoność:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Przebieg procesu eksmisji przez komunikację grupy Galera dla podzielonego węzła podczas problemów z siecią można podsumować w następujący sposób:
- Rozłącza się z klastrem po gmcast.peer_timeout .
- Podejrzewa inne węzły po evs.suspect_timeout .
- Pobiera nowy widok klastra.
- Wykonuje obliczenia kworum w celu określenia stanu węzła.
- Obniża węzeł z SYNCED na OPEN.
- Próbuje ponownie połączyć się z głównym komponentem (innymi węzłami Galera) w tle.
Z perspektywy podstawowego komponentu
Odpowiednio na galera1 i galera3, po gmcast.peer_timeout=PT3S , w dzienniku błędów MySQL pojawia się:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Po przejściu evs.suspect_timeout =PT5S , galera2 jest podejrzewana o śmierć przez galera3 (i galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera sprawdza, czy inne węzły odpowiadają na komunikację grupową na galera3, stwierdza, że galera1 jest w stanie podstawowym i stabilnym:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera zmienia widok klastra tego węzła (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera następnie usuwa partycjonowany węzeł z podstawowego komponentu:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Nowy komponent podstawowy składa się teraz z dwóch węzłów, galera1 i galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Główny składnik wymieni stan między sobą, aby uzgodnić nowy widok klastra i stan globalny:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera oblicza i weryfikuje kworum wymiany między członkami online:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera aktualizuje nowy widok klastra i stan globalny po wykluczeniu galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)W tym momencie zarówno galera1, jak i galera3 będą zgłaszać podobny globalny status:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Wymieniają problematycznego członka w wsrep_evs_delayed status. Ponieważ stan lokalny to „Zsynchronizowany”, węzły te działają i możesz przekierować połączenia klientów z galera2 do dowolnego z nich. Jeśli ten krok jest niewygodny, rozważ użycie modułu równoważenia obciążenia znajdującego się przed bazą danych, aby uprościć punkt końcowy połączenia od klientów.
Odzyskiwanie i łączenie węzłów
Podzielony na partycje węzeł Galera będzie w nieskończoność próbował nawiązać połączenie z komponentem podstawowym. Opróżnijmy reguły iptables na galera2, aby umożliwić połączenie z pozostałymi węzłami:
# on galera2
$ iptables -FGdy węzeł będzie w stanie połączyć się z jednym z węzłów, Galera automatycznie rozpocznie ponowne nawiązywanie komunikacji grupowej:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableWęzeł galera2 połączy się następnie z jednym z komponentów podstawowych (w tym przypadku jest to galera1, identyfikator węzła 737422d6), aby uzyskać bieżący widok klastra i stan węzłów:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera przeprowadzi następnie wymianę stanów z resztą członków, którzy mogą tworzyć podstawowy komponent:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Wymiana stanów umożliwia galera2 obliczenie kworum i uzyskanie następującego wyniku:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera następnie zmieni stan węzła lokalnego z OTWARTY na PODSTAWOWY, aby rozpocząć i nawiązać połączenie węzła z komponentem podstawowym:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Jak podano w powyższym wierszu, Galera oblicza lukę, jak daleko węzeł jest za klastrem. Ten węzeł wymaga transferu stanu, aby dogonić zestaw zapisów o numerze 2836958 z 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera przygotowuje odbiornik IST na porcie 4568 w tym węźle i prosi każdy zsynchronizowany węzeł w klastrze, aby został dawcą. W takim przypadku Galera automatycznie wybiera galera3 (192.168.55.173) lub może również wybrać dawcę z listy w sekcji wsrep_sst_donor (jeśli zdefiniowano) dla operacji synchronizacji:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Następnie zmieni stan węzła lokalnego z PRIMARY na JOINER. Na tym etapie galera2 otrzymuje żądanie przeniesienia stanu i zaczyna buforować zestawy zapisu:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetWęzeł galera2 zaczyna otrzymywać brakujące zestawy zapisu z gcache wybranego dawcy (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Gdy wszystkie brakujące zestawy zapisu zostaną odebrane i zastosowane, Galera będzie promować galera2 jako POŁĄCZONĄ do kolejnego numeru 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Węzeł stosuje wszystkie buforowane zestawy zapisu w swojej kolejce podrzędnej i kończy nadrabianie zaległości w klastrze. Jego kolejka slave jest teraz pusta. Galera będzie promować galera2 do SYNCED, co oznacza, że węzeł działa i jest gotowy do obsługi klientów:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsW tym momencie wszystkie węzły znów działają. Możesz zweryfikować, używając następujących oświadczeń na galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size zgłoszone jako 3, a status klastra to Podstawowy, co oznacza, że galera2 jest częścią Podstawowego Komponentu. wsrep_evs_delayed również został wyczyszczony, a stan lokalny jest teraz zsynchronizowany.
Przebieg procesu odzyskiwania dla partycjonowanego węzła podczas problemów z siecią można podsumować w następujący sposób:
- Przywraca komunikację grupową z innymi węzłami.
- Pobiera widok klastra z jednego z podstawowych komponentów.
- Dokonuje wymiany stanu z komponentem podstawowym i oblicza kworum.
- Zmienia stan węzła lokalnego z OPEN na PRIMARY.
- Oblicza lukę między węzłem lokalnym a klastrem.
- Zmienia stan węzła lokalnego z PRIMARY na JOINER.
- Przygotowuje odbiornik/odbiornik IST na porcie 4568.
- Prosi o przeniesienie stanu za pośrednictwem IST i wybiera dawcę.
- Rozpoczyna odbieranie i stosowanie brakującego zbioru zapisu z pamięci gcache wybranego dawcy.
- Zmienia stan węzła lokalnego z JOINER na JOINED.
- Dopasowuje się do klastra, stosując buforowane zestawy zapisu w kolejce podrzędnej.
- Zmienia stan lokalnego węzła z POŁĄCZONEGO na Zsynchronizowany.
Awaria klastra
Klaster Galera jest uważany za uszkodzony, jeśli nie jest dostępny żaden element podstawowy (PC). Rozważ podobny trzywęzłowy klaster Galera, jak pokazano na poniższym diagramie:
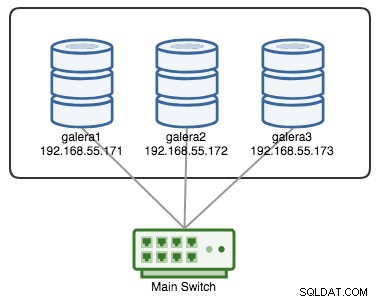
Klaster jest uważany za działający, jeśli wszystkie węzły lub większość węzłów jest w trybie online. Online oznacza, że mogą widzieć się nawzajem przez ruch replikacji Galera lub komunikację grupową. Jeśli żaden ruch nie przychodzi i nie wychodzi z węzła, klaster wyśle sygnał pulsu, aby węzeł odpowiedział w odpowiednim czasie. W przeciwnym razie zostanie umieszczony na liście opóźnień lub podejrzanych, zgodnie z odpowiedzią węzła.
Jeśli węzeł ulegnie awarii, powiedzmy, że węzeł C, klaster będzie nadal działał, ponieważ węzły A i B są nadal w kworum z 2 głosami na 3, aby utworzyć element podstawowy. Powinieneś uzyskać następujący stan klastra na A i B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Jeśli powiedzmy, że główny przełącznik uległ awarii, jak pokazano na poniższym diagramie:
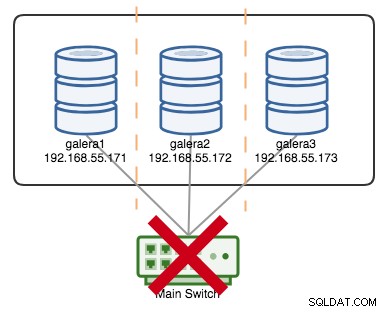
W tym momencie każdy pojedynczy węzeł traci komunikację ze sobą, a stan klastra zostanie zgłoszony jako inny niż podstawowy na wszystkich węzłach (tak jak w przypadku galera2 w poprzednim przypadku). Każdy węzeł obliczyłby kworum i dowiedziałby się, że jest mniejszością (1 głos z 3), tracąc w ten sposób kworum, co oznacza, że nie powstaje żaden element podstawowy, a w konsekwencji wszystkie węzły odmawiają obsługi jakichkolwiek danych. Jest to uznawane za awarię klastra.
Gdy problem z siecią zostanie rozwiązany, Galera automatycznie ponownie nawiąże komunikację między członkami, wymieni stany węzłów i określi możliwość zreformowania podstawowego komponentu, porównując stan węzła, UUID i seqnos. Jeśli istnieje prawdopodobieństwo, Galera połączy podstawowe komponenty, jak pokazano w następujących wierszach:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
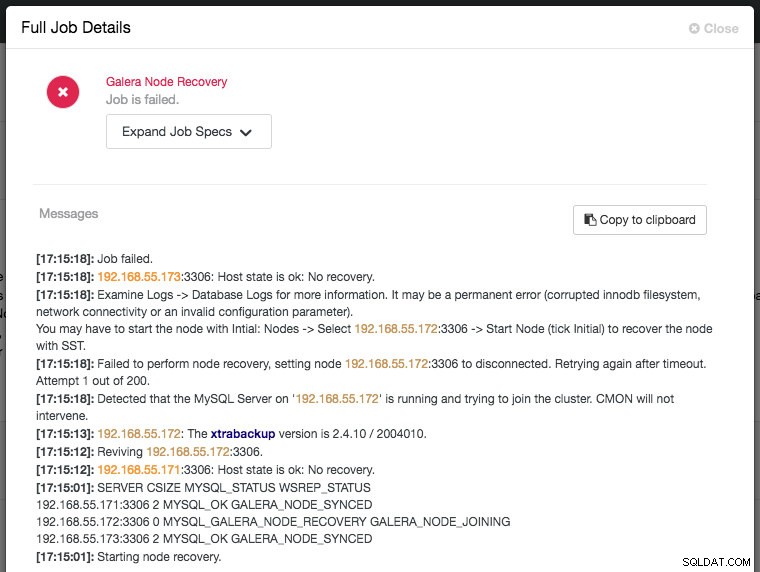
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Wniosek
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.