Być może słyszałeś o określeniu „rozszczepiony mózg”. Co to jest? Jak to wpływa na twoje klastry? W tym poście na blogu omówimy, co to właściwie jest, jakie zagrożenie może stanowić dla Twojej bazy danych, jak możemy temu zapobiec, a jeśli wszystko pójdzie nie tak, jak z niego odzyskać.
Dawno minęły czasy pojedynczych instancji, obecnie prawie wszystkie bazy danych działają w grupach replikacji lub klastrach. Jest to świetne rozwiązanie dla wysokiej dostępności i skalowalności, ale rozproszona baza danych wprowadza nowe zagrożenia i ograniczenia. Jednym ze śmiertelnych przypadków jest podział sieci. Wyobraź sobie klaster wielu węzłów, który z powodu problemów z siecią został podzielony na dwie części. Z oczywistych względów (spójność danych) obie części nie powinny obsługiwać ruchu w tym samym czasie, ponieważ są od siebie odizolowane i nie można między nimi przenosić danych. Jest to również błędne z punktu widzenia aplikacji - nawet jeśli w końcu istniałby sposób na synchronizację danych (chociaż uzgadnianie 2 zestawów danych nie jest trywialne). Przez chwilę część aplikacji nie była świadoma zmian wprowadzonych przez inne hosty aplikacji, które uzyskują dostęp do innej części klastra bazy danych. Może to prowadzić do poważnych problemów.
Stan, w którym klaster został podzielony na dwie lub więcej części, które chcą zaakceptować zapisy, nazywa się „rozszczepionym mózgiem”.
Największym problemem z podzielonym mózgiem jest dryf danych, ponieważ zapisy mają miejsce w obu częściach klastra. Żaden ze smaków MySQL nie zapewnia zautomatyzowanych sposobów łączenia zbiorów danych, które się rozbieżne. Takiej funkcji nie znajdziesz w replikacji MySQL, Group Replication czy Galera. Gdy dane się rozejdą, jedyną opcją jest użycie jednej z części klastra jako źródła prawdy i odrzucenie zmian wykonanych na drugiej części - chyba że możemy wykonać jakiś ręczny proces w celu scalenia danych.
Dlatego zaczniemy od tego, jak zapobiec rozszczepieniu mózgu. Jest to o wiele łatwiejsze niż naprawianie wszelkich rozbieżności danych.
Jak zapobiegać rozszczepieniu mózgu
Dokładne rozwiązanie zależy od typu bazy danych i konfiguracji środowiska. Przyjrzymy się niektórym z najczęstszych przypadków klastra Galera i replikacji MySQL.
Klaster Galera
Galera ma wbudowany „wyłącznik” do obsługi podzielonego mózgu:opiera się na mechanizmie kworum. Jeśli większość (50% + 1) węzłów jest dostępna w klastrze, Galera będzie działać normalnie. W przypadku braku większości Galera przestanie obsługiwać ruch i przejdzie w tzw. stan „niepodstawowy”. To prawie wszystko, czego potrzebujesz, aby poradzić sobie z rozszczepieniem mózgu podczas korzystania z Galery. Jasne, istnieją ręczne metody zmuszania Galery do stanu „Podstawowy”, nawet jeśli nie ma większości. Chodzi o to, że jeśli tego nie zrobisz, powinieneś być bezpieczny.
Sposób obliczania kworum ma ważne reperkusje — na poziomie pojedynczego centrum danych chcesz mieć nieparzystą liczbę węzłów. Trzy węzły zapewniają tolerancję na awarię jednego węzła (2 węzły spełniają wymóg dostępności ponad 50% węzłów w klastrze). Pięć węzłów daje tolerancję na awarię dwóch węzłów (5 - 2 =3, co stanowi ponad 50% z 5 węzłów). Z drugiej strony użycie czterech węzłów nie poprawi twojej tolerancji w porównaniu z klastrem trzech węzłów. Nadal poradzi sobie tylko z awarią jednego węzła (4 - 1 =3, ponad 50% z 4), podczas gdy awaria dwóch węzłów spowoduje, że klaster będzie bezużyteczny (4 - 2 =2, tylko 50%, nie więcej).
Wdrażając klaster Galera w jednym centrum danych, pamiętaj, że najlepiej byłoby rozdzielić węzły w wielu strefach dostępności (oddzielne źródło zasilania, sieć itp.) — o ile istnieją w Twoim centrum danych, czyli . Prosta konfiguracja może wyglądać jak poniżej:
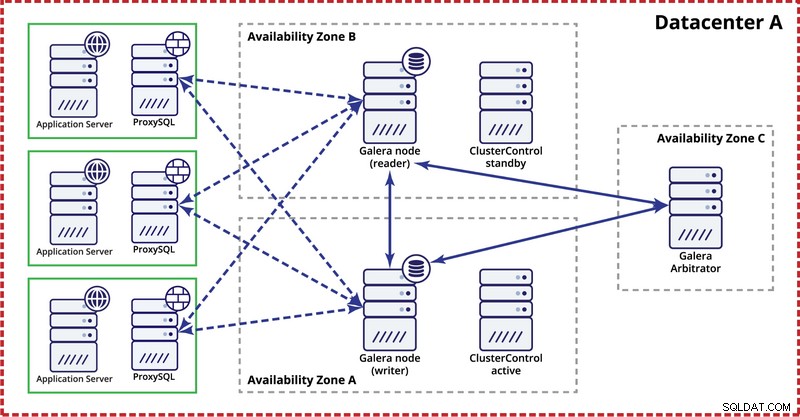
Na poziomie wielu centrów danych te rozważania mają również zastosowanie. Jeśli chcesz, aby klaster Galera automatycznie obsługiwał awarie centrów danych, użyj nieparzystej liczby centrów danych. Aby obniżyć koszty, w jednym z nich zamiast węzła bazy danych można użyć arbitra Galera. Arbiter Galera (garbd) to proces, który bierze udział w obliczeniu kworum, ale nie zawiera żadnych danych. Dzięki temu można go używać nawet w bardzo małych instancjach, ponieważ nie wymaga dużych zasobów — chociaż łączność sieciowa musi być dobra, ponieważ „widzi” cały ruch związany z replikacją. Przykładowa konfiguracja może wyglądać jak na poniższym diagramie:
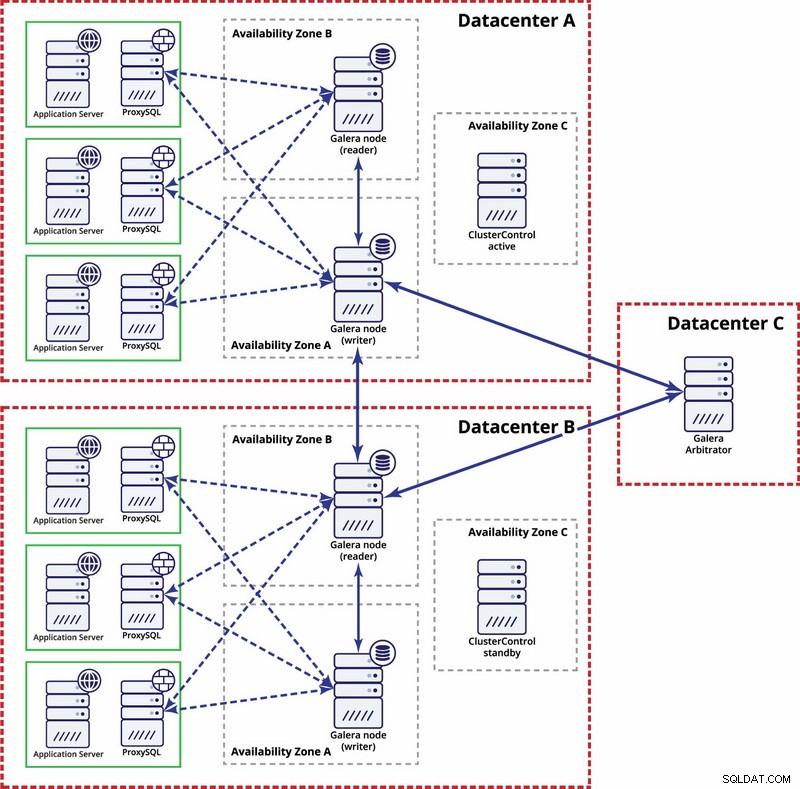
Replikacja MySQL
W przypadku replikacji MySQL największym problemem jest brak wbudowanego mechanizmu kworum, jak to ma miejsce w klastrze Galera. Dlatego wymaganych jest więcej kroków, aby upewnić się, że rozszczepienie mózgu nie wpłynie na twoją konfigurację.
Jedną z metod jest uniknięcie automatycznych przełączeń awaryjnych między centrami danych. Możesz skonfigurować swoje rozwiązanie do przełączania awaryjnego (może to być za pośrednictwem ClusterControl, MHA lub Orchestrator) do przełączania awaryjnego tylko w obrębie jednego centrum danych. Jeśli nastąpiła pełna awaria centrum danych, to od administratora zależy, jak przełączyć się w tryb awaryjny i jak zapewnić, że serwery w uszkodzonym centrum danych nie będą używane.
Istnieją opcje, aby uczynić to bardziej zautomatyzowanym. Możesz użyć Consul do przechowywania danych o węzłach w konfiguracji replikacji oraz o tym, który z nich jest masterem. Następnie administrator (lub za pomocą skryptów) zaktualizuje ten wpis i przeniesie zapisy do drugiego centrum danych. Możesz skorzystać z konfiguracji Orchestrator/Raft, w której węzły Orchestrator mogą być rozmieszczone w wielu centrach danych i wykrywać podział mózgu. Na tej podstawie możesz podejmować różne działania, takie jak, jak wspomnieliśmy wcześniej, aktualizować wpisy w naszym konsulu lub itp. Chodzi o to, że jest to znacznie bardziej złożone środowisko do konfiguracji i automatyzacji niż klaster Galera. Poniżej znajduje się przykład konfiguracji wielu centrów danych dla replikacji MySQL.
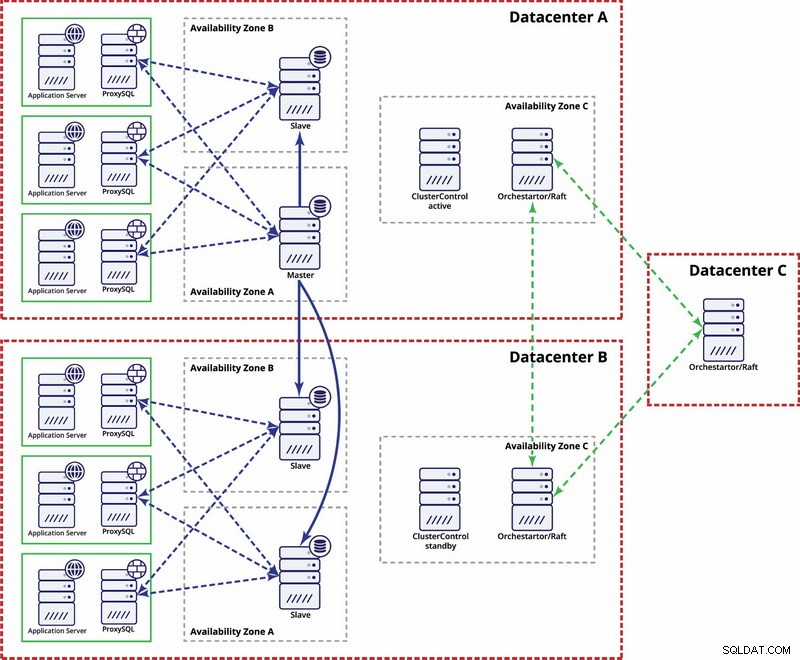
Pamiętaj, że nadal musisz tworzyć skrypty, aby to działało, tj. monitorować węzły programu Orchestrator pod kątem podzielonego mózgu i podejmować niezbędne działania w celu wdrożenia STONITH oraz upewnić się, że master w centrum danych A nie będzie używany po zbieżności sieci i łączności zostać przywrócone.
Split Brain Happened – co dalej?
Zdarzył się najgorszy scenariusz i mamy dryf danych. Postaramy się podpowiedzieć, co można tutaj zrobić. Niestety, dokładne kroki będą zależeć głównie od projektu schematu, więc nie będzie możliwe napisanie dokładnego przewodnika.
Należy pamiętać, że ostatecznym celem będzie skopiowanie danych z jednego wzorca do drugiego i odtworzenie wszystkich relacji między tabelami.
Przede wszystkim musisz określić, który węzeł będzie nadal obsługiwał dane jako master. Jest to zbiór danych, do którego połączysz dane przechowywane na innej „głównej” instancji. Gdy to zrobisz, musisz zidentyfikować dane ze starego wzorca, których brakuje w bieżącym wzorcu. Będzie to praca ręczna. Jeśli masz w tabelach sygnatury czasowe, możesz je wykorzystać do zlokalizowania brakujących danych. Docelowo logi binarne będą zawierać wszystkie modyfikacje danych, więc możesz na nich polegać. Być może będziesz musiał również polegać na swojej znajomości struktury danych i relacji między tabelami. Jeśli dane są znormalizowane, jeden rekord w jednej tabeli może być powiązany z rekordami w innych tabelach. Na przykład Twoja aplikacja może wstawić dane do tabeli „użytkownik”, która jest powiązana z tabelą „adres”, używając identyfikatora użytkownika. Będziesz musiał znaleźć wszystkie powiązane wiersze i wyodrębnić je.
Następnym krokiem będzie załadowanie tych danych do nowego mastera. Nadchodzi trudna część - jeśli wcześniej przygotowałeś swoje ustawienia, może to być po prostu kwestia uruchomienia kilku wstawek. Jeśli nie, może to być dość skomplikowane. Chodzi o klucz podstawowy i unikalne wartości indeksu. Jeśli wartości klucza głównego są generowane jako unikalne na każdym serwerze przy użyciu jakiegoś generatora UUID lub przy użyciu ustawień auto_increment_increment i auto_increment_offset w MySQL, możesz być pewien, że dane ze starego wzorca, który musisz wstawić, nie spowodują klucza podstawowego lub unikalnego kluczowe konflikty z danymi na nowym wzorcu. W przeciwnym razie może być konieczne ręczne zmodyfikowanie danych ze starego wzorca, aby upewnić się, że można je poprawnie wstawić. Brzmi skomplikowanie, więc spójrzmy na przykład.
Wyobraźmy sobie, że wstawiamy wiersze za pomocą auto_increment w węźle A, który jest wzorcem. Dla uproszczenia skupimy się tylko na jednym rzędzie. Istnieją kolumny „id” i „wartość”.
Jeśli wstawimy go bez żadnej konkretnej konfiguracji, zobaczymy wpisy jak poniżej:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Te będą replikować się do niewolnika (B). Jeśli dojdzie do podziału mózgu i zapisy będą wykonywane zarówno na starym, jak i nowym wzorcu, otrzymamy następującą sytuację:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Jak widać, nie ma sposobu, aby po prostu zrzucić rekordy o identyfikatorach 1004, 1005 i 1006 z węzła A i przechowywać je w węźle B, ponieważ otrzymamy zduplikowane wpisy klucza podstawowego. Należy zmienić wartości kolumny id w wierszach, które zostaną wstawione na wartość większą niż maksymalna wartość kolumny id z tabeli. To wszystko, czego potrzeba do pojedynczych rzędów. W przypadku bardziej złożonych relacji, w których zaangażowanych jest wiele tabel, konieczne może być wprowadzenie zmian w wielu lokalizacjach.
Z drugiej strony, gdybyśmy przewidzieli ten potencjalny problem i skonfigurowali nasze węzły do przechowywania nieparzystych identyfikatorów w węźle A, a parzystych w węźle B, problem byłby o wiele łatwiejszy do rozwiązania.
Węzeł A został skonfigurowany z auto_increment_offset =1 i auto_increment_increment =2
Węzeł B został skonfigurowany z auto_increment_offset =2 i auto_increment_increment =2
Tak wyglądałyby dane w węźle A przed podziałem mózgu:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Kiedy nastąpi rozszczepienie mózgu, będzie to wyglądać jak poniżej.
Węzeł A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Węzeł B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Teraz możemy łatwo skopiować brakujące dane z węzła A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’I załaduj go do węzła B, kończąc z następującym zestawem danych:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Jasne, wiersze nie są w oryginalnej kolejności, ale powinno być w porządku. W najgorszym przypadku będziesz musiał uporządkować według kolumny „wartość” w zapytaniach i być może dodać do niej indeks, aby przyspieszyć sortowanie.
Teraz wyobraź sobie setki lub tysiące wierszy i wysoce znormalizowaną strukturę tabeli - przywrócenie jednego wiersza może oznaczać, że będziesz musiał przywrócić kilka z nich w dodatkowych tabelach. Przy potrzebie zmiany identyfikatorów (ponieważ nie masz ustawionych ustawień ochronnych) we wszystkich powiązanych wierszach i wszystko to jest pracą ręczną, możesz sobie wyobrazić, że nie jest to najlepsza sytuacja, w której można się znaleźć. jest to proces podatny na błędy. Na szczęście, jak omówiliśmy na początku, istnieją środki, aby zminimalizować szanse, że podzielony mózg wpłynie na twój system lub zmniejszyć pracę, którą należy wykonać, aby zsynchronizować węzły. Upewnij się, że ich używasz i bądź przygotowany.