Błędy stron to powszechny błąd, który najczęściej występuje w dużych aplikacjach obejmujących duże ilości danych. Ma to miejsce, gdy baza danych MongoDB odczytuje dane z pamięci fizycznej, a nie z pamięci wirtualnej. Błędy strony występują w momencie, gdy MongoDB chce pobrać dane, które nie są dostępne w aktywnej pamięci bazy danych, stąd zmuszają do odczytu z dysku. Stwarza to duże opóźnienie dla operacji przepustowości, przez co zapytania wyglądają, jakby były opóźnione.
Dostosowywanie wydajności MongoDB przez dostrajanie jest kluczowym elementem, który optymalizuje wykonywanie aplikacji. Bazy danych zostały ulepszone do pracy z informacjami przechowywanymi na dysku, jednak zwykle buforują duże ilości danych w pamięci RAM, próbując uzyskać dostęp do dysku. Przechowywanie i uzyskiwanie dostępu do danych z bazy danych jest kosztowne, dlatego informacje muszą być najpierw zapisane na dysku przed zezwoleniem aplikacjom na dostęp do nich. Z uwagi na fakt, że dyski są wolniejsze w porównaniu z pamięcią podręczną danych RAM, proces ten zajmuje dużo czasu. Dlatego MongoDB ma na celu zgłaszanie błędów stron jako podsumowanie wszystkich incydentów w ciągu jednej sekundy
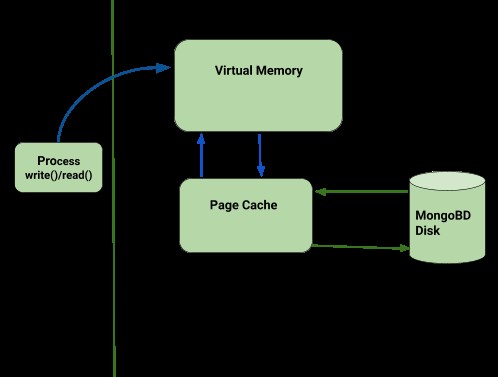
Topologia przenoszenia danych w MongoDB
Dane z klienta są przenoszone do pamięci wirtualnej, gdzie pamięć podręczna strony odczytuje je w trakcie zapisywania, a następnie dane są przechowywane na dysku, jak pokazano na poniższym diagramie.
Jak znaleźć błędy strony MongoDB
Błędy stron można wykryć dzięki wydajności blokowania, która zapewnia spójność danych w MongoDB. Gdy dana operacja jest w kolejce lub działa przez długi czas, wydajność MongoDB spada, a operacja spowalnia w oczekiwaniu na blokadę. Prowadzi to do spowolnienia, ponieważ opóźnienia związane z blokadą są sporadyczne i czasami wpływają na wydajność aplikacji. Blokada wpływa na wydajność aplikacji, gdy blokady są podzielone (locks.timeAcquiringMicros przez locks.acquireWaitCount), co daje średni czas oczekiwania na dany tryb blokady. Locks.deadLockCount podaje sumę wszystkich przebytych impasów w akwizycji zamków. Biorąc pod uwagę, że globalLock.totalTime jest harmonijnie wysoki, istnieje wiele żądań oczekujących blokady. Im więcej żądań czeka na blokadę, tym więcej pamięci RAM jest zużywane, co prowadzi do błędów strony.
Możesz również użyć mem.mapped, który umożliwia programistom analizę całkowitej pamięci używanej przez mongod. Mem.mapped to operator serwera służący do sprawdzania ilości pamięci w megabajtach (MB) w aparacie pamięci masowej MMAPv1. Jeśli operator mem.mapped pokazuje wartość A większą niż całkowita ilość pamięci systemowej, wystąpi błąd strony, ponieważ tak duże użycie pamięci doprowadzi do błędu strony w bazie danych.
Jak występują błędy strony w MongoDB
Ładowanie stron w MongoDB zależy od dostępności wolnej pamięci, w przypadku braku wolnej pamięci system operacyjny musi:
- Poszukaj strony, której baza danych przestała używać i zapisz ją na dysku pamięci.
- Załaduj żądaną stronę do pamięci po odczytaniu jej z dysku.
Te dwie czynności mają miejsce podczas wczytywania stron, a zatem zajmują dużo czasu w porównaniu z odczytem w aktywnej pamięci, co prowadzi do wystąpienia błędów strony.
Rozwiązywanie błędów strony MongoDB
Oto kilka sposobów rozwiązywania błędów stron:
- Skalowanie w pionie do urządzeń z wystarczającą ilością pamięci RAM lub skalowanie w poziomie: gdy dla danego zestawu danych nie ma wystarczającej ilości pamięci RAM, prawidłowym podejściem jest zwiększenie pamięci RAM przez skalowanie w pionie do urządzeń z większą ilością pamięci RAM, aby dodać więcej zasobów do serwera. Skalowanie w pionie jest jednym z najlepszych i łatwych sposobów na zwiększenie wydajności MongoDB poprzez nierozkładanie obciążenia na wiele serwerów. Ponieważ skalowanie w pionie dodaje więcej pamięci RAM, skalowanie w poziomie umożliwia dodanie większej liczby fragmentów do klastra podzielonego na fragmenty. Mówiąc prościej, skalowanie poziome polega na podzieleniu bazy danych na różne porcje i przechowywaniu na wielu serwerach. Skalowanie poziome umożliwia programiście dodawanie większej liczby serwerów w locie, co znacznie zwiększa wydajność bazy danych, ponieważ nie powoduje zerowych przestojów. Skalowanie w pionie i w poziomie zmniejsza rozwiązywanie błędów strony poprzez zwiększenie pamięci, która działa podczas pracy z bazą danych.
- Prawidłowo indeksuj dane: używaj odpowiednich indeksów, aby zapewnić wydajne zapytania, które nie powodują skanowania kolekcji. Właściwe indeksowanie zapewnia, że baza danych nie iteruje po każdym dokumencie w kolekcji, a tym samym rozwiązuje możliwe wystąpienie błędu strony. Skanowanie kolekcji powoduje błąd strony, ponieważ cała kolekcja jest sprawdzana przez aparat zapytań podczas wczytywania do pamięci RAM. Większość dokumentów w skanowaniu kolekcji nie jest zwracana w aplikacji, co powoduje niepotrzebne błędy stron przy każdym kolejnym zapytaniu, które nie jest łatwe do uniknięcia. Ponadto nadmiar indeksów może również prowadzić do nieefektywnego wykorzystania pamięci RAM, co może prowadzić do błędu strony. Dlatego prawidłowe indeksowanie ma kluczowe znaczenie, jeśli programista zamierza rozwiązać błędy związane z błędami strony. MongoDB oferuje pomoc w określeniu indeksów, które należy wdrożyć podczas korzystania z bazy danych. Oferują zarówno Slow Query Analyzer, który dostarcza potrzebnych informacji na temat indeksowania dla użytkowników i współużytkowników.
- Migracja do najnowszej wersji MongoDB, a następnie przeniesienie aplikacji do WiredTiger. Jest to konieczne, jeśli zamierzasz uniknąć wystąpienia błędu strony, ponieważ błędy strony występują tylko w aparatach pamięci masowej MMAPv1, w przeciwieństwie do nowszych wersji i WiredTiger. Silnik pamięci masowej MMAPv1 jest przestarzały i MongoDB już go nie obsługuje. WiredTiger jest obecnie domyślnym silnikiem pamięci masowej w MongoDB i ma funkcję MultiVersion Concurrency Control, co czyni go znacznie lepszym w porównaniu z silnikiem pamięci masowej MMAPv1. Dzięki WiredTiger MongoDB może używać zarówno pamięci podręcznej systemu plików, jak i wewnętrznej pamięci podręcznej WiredTiger, która ma bardzo duży rozmiar 1 GB (50% 0f (RAM - 1 GB)) lub 256 MB.
- Śledź całkowitą dostępną pamięć RAM do użytku w systemie. Można to zrobić za pomocą usług takich jak monitorowanie New Relic Google Cloud Monitoring. Ponadto BindPlane może być używany z wymienionymi usługami monitorowania chmury. Korzystanie z systemu monitorowania to proaktywny środek, który umożliwia przeciwdziałanie błędom stron przed ich wystąpieniem, a nie reagowanie na występujące błędy stron. BindPlane umożliwia monitorowi ustawienie ciągłych alertów o wystąpieniu błędów stron, alerty te również informują o liczbie indeksów, rozmiarze indeksu i rozmiarze pliku.
- Zapewnienie, że dane są skonfigurowane w bieżącym zestawie roboczym i że nie będą używać więcej pamięci RAM niż zalecane. MongoDB to system baz danych, który działa najlepiej, gdy często używane dane i indeksy mogą idealnie zmieścić się w przypisanej pamięci. Rozmiar pamięci RAM jest kluczowym aspektem podczas optymalizacji wydajności bazy danych, dlatego przed wdrożeniem aplikacji należy upewnić się, że zawsze jest wystarczająca ilość pamięci RAM.
- Rozprowadzanie obciążenia między instancjami mongod poprzez dodawanie fragmentów lub wdrażanie klastra podzielonego na fragmenty. Niezwykle istotne jest umożliwienie zacieniania miejsca, w którym znajduje się docelowa kolekcja. Najpierw połącz się z mongosami w powłoce mongo i użyj poniższej metody.
-
sh.shardCollection()Następnie utwórz indeks tą metodą.
Utworzony indeks obsługuje klucz fragmentu, czyli jeśli utworzona kolekcja już odebrała lub przechowała jakieś dane. Jeśli jednak kolekcja nie zawiera danych (pusta), użyj poniższej metody, aby zindeksować ją jako część ssh.shardCollection:sh.shardCollection()db.collection.createIndex(keys, options) - Po tym następuje jedna z dwóch strategii dostarczanych przez mongoDB.
- Cieniowanie haszowane
sh.shardCollection("<database>.<collection>", { <shard key field> : "hashed" } ) - Cieniowanie na podstawie zakresu
sh.shardCollection("<database>.<collection>", { <shard key field> : 1, ... } )
- Cieniowanie haszowane
-
Jak zapobiegać błędom strony MongoDB
- Dodaj fragmenty lub wdróż sharded klaster, aby rozłożyć obciążenie
- Miej wystarczającą ilość pamięci RAM dla swojej aplikacji przed jej wdrożeniem
- Przejdź do nowszych wersji MongoDB, a następnie przejdź do WiredTiger
- Skaluj w pionie lub poziomie w przypadku urządzenia z większą ilością pamięci RAM
- Użyj zalecanej pamięci RAM i śledź używane miejsce w pamięci RAM
Wnioski
Kilka liczby błędów stronicowania (samych) zajmuje niewiele czasu, jednak w sytuacji, gdy występuje wiele błędów stronicowania (zagregowane), oznacza to, że baza danych odczytuje dużą ilość danych w dysk. Gdy nastąpi agregacja, pojawi się więcej blokad odczytu MongoBD, które doprowadzą do błędu strony.
W przypadku korzystania z MongoDB wielkość pamięci RAM systemu i liczba zapytań mogą znacznie wpłynąć na wydajność aplikacji. Wydajność aplikacji w MongoDB w dużym stopniu zależy od dostępnej pamięci RAM w pamięci fizycznej, co ma wpływ na czas potrzebny aplikacji na wykonanie pojedynczego zapytania. Przy wystarczającej ilości pamięci RAM liczba błędów stron jest zmniejszona, a wydajność aplikacji zwiększona.



