Ogólna strategia, której używa silnik bazy danych SQL Server do utrzymywania zsynchronizowanego widoku indeksowanego z jego tabelami bazowymi – którą opisałem bardziej szczegółowo w moim ostatnim poście – polega na wykonywaniu konserwacji przyrostowej widoku za każdym razem, gdy operacja zmiany danych ma miejsce w jednej z tabel, do których odwołuje się widok. Ogólnie rzecz biorąc, chodzi o:
- Zbierz informacje o zmianach w tabeli podstawowej
- Zastosuj projekcje, filtry i połączenia zdefiniowane w widoku
- Agregacja zmian według klucza klastrowanego widoku indeksowanego
- Zdecyduj, czy każda zmiana powinna skutkować wstawieniem, aktualizacją lub usunięciem w widoku
- Oblicz wartości do zmiany, dodania lub usunięcia w widoku
- Zastosuj zmiany widoku
Lub jeszcze bardziej zwięźle (choć z ryzykiem rażącego uproszczenia):
- Oblicz przyrostowe efekty wyświetlania oryginalnych modyfikacji danych;
- Zastosuj te zmiany do widoku
Jest to zwykle znacznie bardziej wydajna strategia niż przebudowanie całego widoku po każdej podstawowej zmianie danych (opcja bezpieczna, ale powolna), ale opiera się na logice aktualizacji przyrostowej, która jest poprawna dla każdej możliwej zmiany danych, w stosunku do każdej możliwej definicji widoku indeksowanego.
Jak sugeruje tytuł, ten artykuł dotyczy interesującego przypadku, w którym logika aktualizacji przyrostowej załamuje się, co skutkuje uszkodzonym indeksowanym widokiem, który nie pasuje już do podstawowych danych. Zanim przejdziemy do samego błędu, musimy szybko przejrzeć agregaty skalarne i wektorowe.
Agregaty skalarne i wektorowe
Jeśli nie znasz tego terminu, istnieją dwa rodzaje agregatów. Agregat powiązany z klauzulą GROUP BY (nawet jeśli lista grup według jest pusta) jest znany jako agregat wektorowy . Agregat bez klauzuli GROUP BY jest znany jako agregat skalarny .
Podczas gdy agregat wektorowy gwarantuje wygenerowanie pojedynczego wiersza wyjściowego dla każdej grupy obecnej w zestawie danych, agregaty skalarne są nieco inne. Agregaty skalarne zawsze utworzyć pojedynczy wiersz wyjściowy, nawet jeśli zestaw wejściowy jest pusty.
Przykład zagregowania wektorów
Poniższy przykład AdventureWorks oblicza dwie agregacje wektorowe (suma i liczba) w pustym zestawie danych wejściowych:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Te zapytania dają następujące dane wyjściowe (bez wierszy):

Wynik jest taki sam, jeśli zastąpimy klauzulę GROUP BY pustym zestawem (wymagany SQL Server 2008 lub nowszy):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
W obu przypadkach plany wykonawcze są identyczne. To jest plan wykonania zapytania zliczającego:
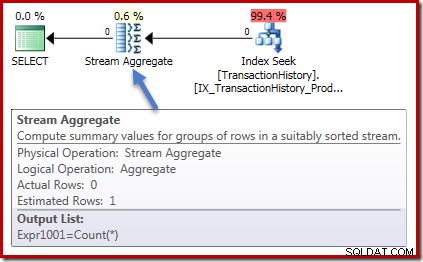
Zero wierszy wejściowych do Stream Aggregate i zero wierszy wychodzących. Plan wykonania sumy wygląda tak:

Ponownie zero wierszy do agregatu i zero wierszy na zewnątrz. Jak dotąd wszystkie dobre, proste rzeczy.
Agregacje skalarne
Teraz spójrz, co się stanie, jeśli całkowicie usuniemy klauzulę GROUP BY z zapytań:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Zamiast pustego wyniku agregacja COUNT daje zero, a SUM zwraca NULL:
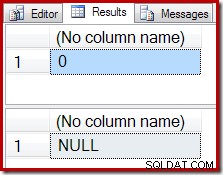
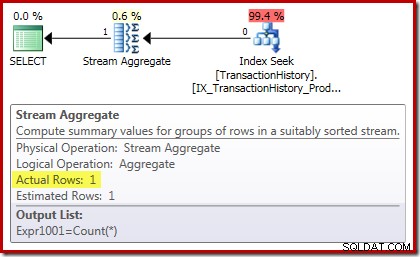
Plan wykonania liczby potwierdza, że zero wierszy wejściowych daje pojedynczy wiersz danych wyjściowych z agregatu Stream:
Plan wykonania sumy jest jeszcze bardziej interesujący:
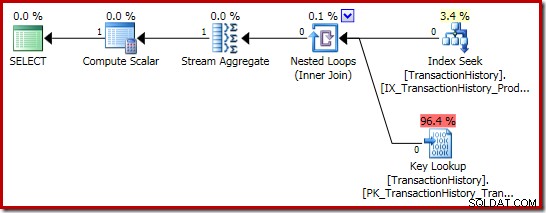
Właściwości Stream Aggregate pokazują, że oprócz sumy, o którą poprosiliśmy, obliczana jest suma liczników:
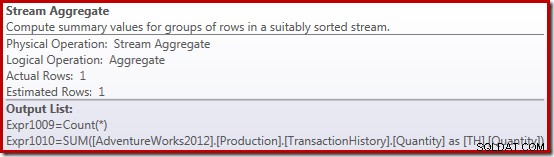
Nowy operator Compute Scalar jest używany do zwracania wartości NULL, jeśli liczba wierszy odebranych przez Stream Aggregate wynosi zero, w przeciwnym razie zwraca sumę napotkanych danych:
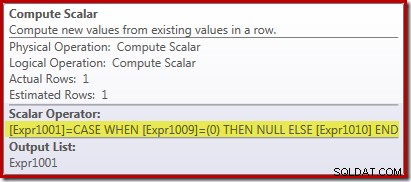
To wszystko może wydawać się trochę dziwne, ale tak to działa:
- Agregacja wektorowa zerowych wierszy zwraca zero wierszy;
- Agregacja skalarna zawsze generuje dokładnie jeden wiersz danych wyjściowych, nawet dla pustego wejścia;
- Liczba skalarna zerowych wierszy wynosi zero; oraz
- Suma skalarna zerowych wierszy wynosi NULL (nie zero).
Ważnym punktem dla naszych obecnych celów jest to, że agregaty skalarne zawsze dają jeden wiersz danych wyjściowych, nawet jeśli oznacza to tworzenie jednego z niczego. Ponadto suma skalarna zerowych wierszy wynosi NULL, a nie zero.
Nawiasem mówiąc, wszystkie te zachowania są „poprawne”. Rzeczy są takie, jakie są, ponieważ standard SQL pierwotnie nie definiował zachowania agregatów skalarnych, pozostawiając to wdrożeniu. SQL Server zachowuje swoją oryginalną implementację ze względu na zgodność wsteczną. Agregaty wektorowe zawsze miały dobrze zdefiniowane zachowania.
Widoki indeksowane i agregacja wektorów
Rozważmy teraz prosty indeksowany widok zawierający kilka (wektorowych) agregatów:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Poniższe zapytania pokazują zawartość tabeli bazowej, wynik zapytania do widoku indeksowanego oraz wynik uruchomienia zapytania widoku na tabeli leżącej u podstaw widoku:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Wyniki to:
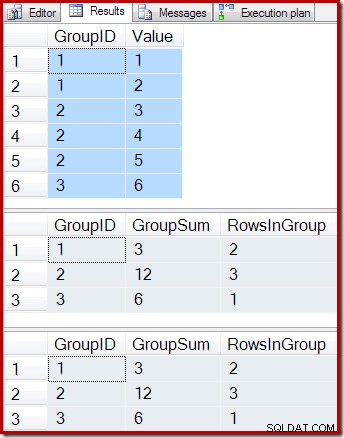
Zgodnie z oczekiwaniami widok indeksowany i zapytanie bazowe zwracają dokładnie te same wyniki. Wyniki będą nadal synchronizowane po wszelkich możliwych zmianach w tabeli podstawowej T1. Aby przypomnieć sobie, jak to wszystko działa, rozważ prosty przypadek dodania jednego nowego wiersza do tabeli bazowej:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Plan wykonania tej wstawki zawiera całą logikę potrzebną do utrzymania zsynchronizowanego widoku indeksowanego:
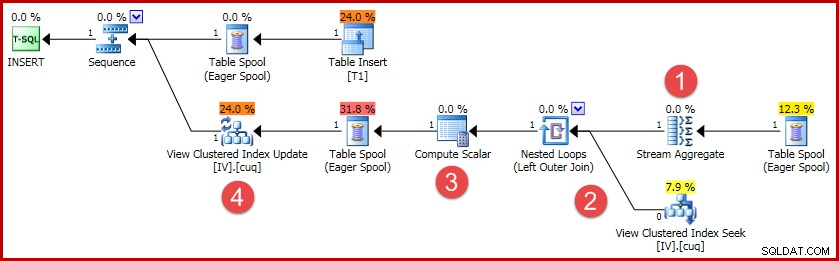
Główne działania w planie to:
- Stream Aggregate oblicza zmiany według klucza indeksowanego widoku
- Złączenie zewnętrzne do widoku łączy podsumowanie zmian z wierszem widoku docelowego, jeśli istnieje
- Skalar obliczeniowy decyduje, czy każda zmiana będzie wymagała wstawienia, aktualizacji lub usunięcia w widoku, i oblicza niezbędne wartości.
- Operator aktualizacji widoku fizycznie wykonuje każdą zmianę w indeksie klastrowym widoku.
Istnieją pewne różnice w planach dla różnych operacji zmian w stosunku do tabeli bazowej (np. aktualizacje i usunięcia), ale ogólna idea synchronizowania widoku pozostaje taka sama:agregacja zmian według klucza widoku, znajdź wiersz widoku, jeśli istnieje, a następnie wykonaj kombinacja operacji wstawiania, aktualizacji i usuwania w indeksie widoku, jeśli to konieczne.
Bez względu na to, jakie zmiany wprowadzisz w tabeli bazowej w tym przykładzie, widok indeksowany pozostanie poprawnie zsynchronizowany — powyższe zapytania NOEXPAND i EXPAND VIEWS zawsze zwrócą ten sam zestaw wyników. Tak zawsze powinno działać.
Widoki indeksowane i agregacja skalarna
Teraz wypróbuj ten przykład, w którym indeksowany widok używa agregacji skalarnej (brak klauzuli GROUP BY w widoku):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Jest to całkowicie legalny widok zindeksowany; podczas tworzenia nie występują żadne błędy. Jest jednak jedna wskazówka, że możemy robić coś trochę dziwnego:kiedy przychodzi czas na zmaterializowanie widoku poprzez utworzenie wymaganego unikalnego indeksu klastrowego, nie ma oczywistej kolumny, którą można wybrać jako klucz. Normalnie wybralibyśmy oczywiście kolumny grupujące z klauzuli GROUP BY widoku.
Powyższy skrypt arbitralnie wybiera kolumnę NumRows. Ten wybór nie jest ważny. Możesz swobodnie tworzyć niepowtarzalny indeks klastrowy w dowolny sposób. Widok będzie zawsze zawierał dokładnie jeden wiersz ze względu na agregaty skalarne, więc nie ma szans na jednoznaczne naruszenie klucza. W tym sensie wybór klucza indeksu widoku jest zbędny, ale mimo to wymagany.
Używając ponownie zapytań testowych z poprzedniego przykładu, widzimy, że widok indeksowany działa poprawnie:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
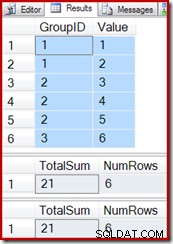
Wstawianie nowego wiersza do tabeli bazowej (tak jak zrobiliśmy to w przypadku indeksowanego widoku zagregowanego wektora) również działa poprawnie:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Plan wykonania jest podobny, ale nie całkiem identyczny:
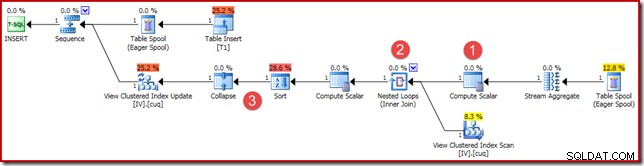
Główne różnice to:
- Ten nowy skalar obliczeniowy jest dostępny z tych samych powodów, co podczas wcześniejszego porównywania wyników agregacji wektorowej i skalarnej:zapewnia zwrócenie sumy NULL (zamiast zera), jeśli agregacja działa na pustym zestawie. Jest to wymagane zachowanie dla sumy skalarnej bez wierszy.
- Złączenie zewnętrzne, które widzieliśmy wcześniej, zostało zastąpione złączem wewnętrznym. W indeksowanym widoku zawsze będzie dokładnie jeden wiersz (ze względu na agregację skalarną), więc nie ma mowy o konieczności zewnętrznego sprzężenia w celu sprawdzenia, czy wiersz widoku jest zgodny, czy nie. Jeden wiersz obecny w widoku zawsze reprezentuje cały zestaw danych. To sprzężenie wewnętrzne nie ma predykatu, więc technicznie jest sprzężeniem krzyżowym (do tabeli z gwarantowanym pojedynczym wierszem).
- Operatory sortowania i zwijania są obecne z przyczyn technicznych opisanych w moim poprzednim artykule na temat konserwacji widoków indeksowanych. Nie wpływają one na prawidłowe działanie konserwacji indeksowanego widoku tutaj.
W rzeczywistości wiele różnych typów operacji zmiany danych może być pomyślnie wykonanych w tym przykładzie względem tabeli bazowej T1; efekty zostaną poprawnie odzwierciedlone w zindeksowanym widoku. Wszystkie poniższe operacje zmiany tabeli bazowej można wykonać, zachowując poprawność indeksowanego widoku:
- Usuń istniejące wiersze
- Zaktualizuj istniejące wiersze
- Wstaw nowe wiersze
Może się to wydawać wyczerpującą listą, ale tak nie jest.
Ujawniono błąd
Problem jest raczej subtelny i dotyczy (jak można się spodziewać) różnych zachowań agregatów wektorowych i skalarnych. Kluczową kwestią jest to, że agregacja skalarna zawsze wygeneruje wiersz wyjściowy, nawet jeśli nie otrzyma żadnych wierszy na wejściu, a suma skalarna pustego zestawu wynosi NULL, a nie zero.
Aby spowodować problem, wystarczy, że nie wstawimy ani nie usuniemy żadnych wierszy w tabeli podstawowej.
To stwierdzenie nie jest tak szalone, jak mogłoby się wydawać.
Chodzi o to, że zapytanie wstawiające lub usuwające, które nie wpływa na żadne wiersze tabeli bazowej, nadal aktualizuje widok ponieważ agregacja strumienia skalarnego w indeksowanej części konserwacji widoku planu zapytania wygeneruje wiersz danych wyjściowych, nawet jeśli jest prezentowany bez danych wejściowych. Skalar obliczeniowy następujący po Stream Aggregate również wygeneruje sumę NULL, gdy liczba wierszy wynosi zero.
Poniższy skrypt demonstruje działanie błędu:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Wynik działania tego skryptu jest pokazany poniżej:
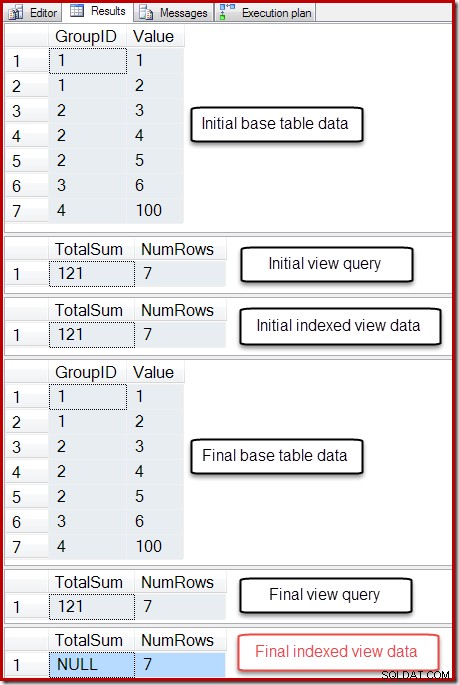
Ostateczny stan kolumny Suma sumy indeksowanego widoku nie jest zgodny z zapytaniem źródłowym widoku lub danymi tabeli podstawowej. Suma NULL uszkodziła widok, co można potwierdzić, uruchamiając polecenie DBCC CHECKTABLE (w widoku indeksowanym).
Plan wykonania odpowiedzialny za korupcję przedstawiono poniżej:
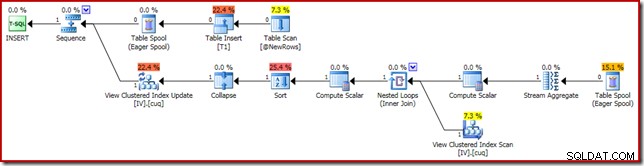
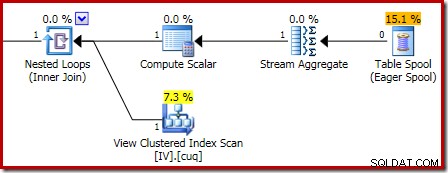
Powiększenie pokazuje dane wejściowe z zerowymi wierszami do Stream Aggregate i jednowierszowe dane wyjściowe:
Jeśli chcesz wypróbować powyższy skrypt korupcji z usuwaniem zamiast wstawiania, oto przykład:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Usunięcie nie wpływa na żadne wiersze tabeli bazowej, ale nadal zmienia kolumnę sumy indeksowanego widoku na NULL.
Uogólnianie błędu
Prawdopodobnie możesz wymyślić dowolną liczbę zapytań wstawiania i usuwania tabeli bazowej, które nie wpływają na żadne wiersze i powodują uszkodzenie tego indeksowanego widoku. Jednak ta sama podstawowa kwestia dotyczy szerszej klasy problemów niż tylko wstawianie i usuwanie, które nie wpływają na wiersze tabeli podstawowej.
Możliwe jest na przykład wygenerowanie tego samego uszkodzenia za pomocą wstawki, która robi dodaj wiersze do tabeli podstawowej. Istotnym składnikiem jest to, że żadne dodane wiersze nie powinny kwalifikować się do widoku . Spowoduje to powstanie pustych danych wejściowych do Stream Aggregate i powodującego uszkodzenie wyniku wiersza NULL z następującego skalaru obliczeniowego.
Jednym ze sposobów na osiągnięcie tego jest umieszczenie w widoku klauzuli WHERE, która odrzuca niektóre wiersze tabeli bazowej:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Biorąc pod uwagę nowe ograniczenie dotyczące identyfikatorów grup zawartych w widoku, następująca wstawka doda wiersze do tabeli podstawowej, ale nadal uszkodzony widok indeksowany będzie miał sumę NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Dane wyjściowe pokazują znane już uszkodzenie indeksu:
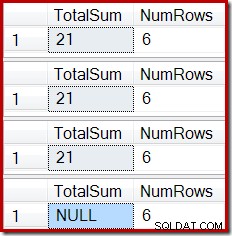
Podobny efekt można uzyskać za pomocą widoku zawierającego jedno lub więcej połączeń wewnętrznych. Dopóki wiersze dodane do tabeli bazowej są odrzucane (na przykład z powodu niepowodzenia dołączenia), Stream Aggregate nie otrzyma żadnych wierszy, skalar obliczeniowy wygeneruje sumę NULL, a widok indeksowany prawdopodobnie zostanie uszkodzony.
Ostateczne myśli
Ten problem nie występuje w przypadku zapytań aktualizujących (przynajmniej o ile mogę to stwierdzić), ale wydaje się, że jest to bardziej przypadek niż projekt — problematyczna agregacja strumienia jest nadal obecna w potencjalnie zagrożonych planach aktualizacji, ale skalar obliczeniowy, który generuje suma NULL nie jest dodawana (lub być może zoptymalizowana). Daj mi znać, jeśli uda Ci się odtworzyć błąd za pomocą zapytania aktualizującego.
Dopóki ten błąd nie zostanie naprawiony (lub być może agregacje skalarne nie będą dozwolone w widokach indeksowanych), należy bardzo uważać na używanie agregatów w widoku indeksowanym bez klauzuli GROUP BY.
Ten artykuł został zainspirowany artykułem Connect przesłanym przez Vladimira Moldovanenko, który był na tyle uprzejmy, że pozostawił komentarz pod moim starym wpisem na blogu (który dotyczy innego korupcji indeksowanego widoku spowodowanego oświadczeniem MERGE). Vladimir używał agregacji skalarnych w widoku indeksowanym z uzasadnionych powodów, więc nie oceniaj zbyt szybko tego błędu jako skrajnego przypadku, którego nigdy nie spotkasz w środowisku produkcyjnym! Dziękuję Vladimirowi za powiadomienie mnie o jego produkcie Connect.