Jak każdy język programowania, T-SQL ma wiele typowych błędów i pułapek, z których niektóre powodują nieprawidłowe wyniki, a inne powodują problemy z wydajnością. W wielu z tych przypadków istnieją najlepsze praktyki, które pomogą Ci uniknąć kłopotów. Przeprowadziłem ankietę wśród innych MVP Microsoft Data Platform, pytając o błędy i pułapki, które często widzą lub które po prostu uważają za szczególnie interesujące, oraz o najlepsze praktyki, które stosują, aby ich uniknąć. Mam wiele ciekawych przypadków.
Serdeczne podziękowania dla Erlanda Sommarskoga, Aarona Bertranda, Alejandro Mesy, Umachandara Jayachandrana (UC), Fabiano Neves Amorima, Milosa Radivojevicia, Simona Sabina, Adama Machanica, Thomasa Grohsera i Chana Ming Mana za podzielenie się swoją wiedzą i doświadczeniem!
Ten artykuł jest pierwszym z serii na ten temat. Każdy artykuł skupia się na określonym temacie. W tym miesiącu skupiam się na błędach, pułapkach i najlepszych praktykach związanych z determinizmem. Obliczenia deterministyczne to takie, które gwarantują powtarzalne wyniki przy tych samych danych wejściowych. Istnieje wiele błędów i pułapek, które wynikają ze stosowania obliczeń niedeterministycznych. W tym artykule omawiam implikacje używania niedeterministycznego porządku, niedeterministycznych funkcji, wielokrotnych odwołań do wyrażeń tabelowych z niedeterministycznymi obliczeniami oraz użycia wyrażeń CASE i funkcji NULLIF z niedeterministycznymi obliczeniami.
Używam przykładowej bazy danych TSQLV5 w wielu przykładach z tej serii.
Porządek niedeterministyczny
Jednym z powszechnych źródeł błędów w T-SQL jest użycie niedeterministycznego porządku. To znaczy, gdy twoje zamówienie według listy nie identyfikuje jednoznacznie wiersza. Może to być zamówienie prezentacji, zamówienia TOP/OFFSET-FETCH lub zamówienie okien.
Weźmy na przykład klasyczny scenariusz stronicowania przy użyciu filtra OFFSET-FETCH. Musisz wykonać zapytanie do tabeli Sales.Orders zwracając jedną stronę zawierającą 10 wierszy na raz, uporządkowanych według daty zamówienia, malejąco (najpierw najnowsze). Dla uproszczenia użyję stałych dla elementów offset i fetch, ale zazwyczaj są to wyrażenia oparte na parametrach wejściowych.
Następujące zapytanie (nazwij je Zapytanie 1) zwraca pierwszą stronę 10 ostatnich zamówień:
UŻYJ TSQLV5; SELECT identyfikator zamówienia, data zamówienia, custid FROM Sprzedaż. Zamówienia ORDER BY data zamówienia DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
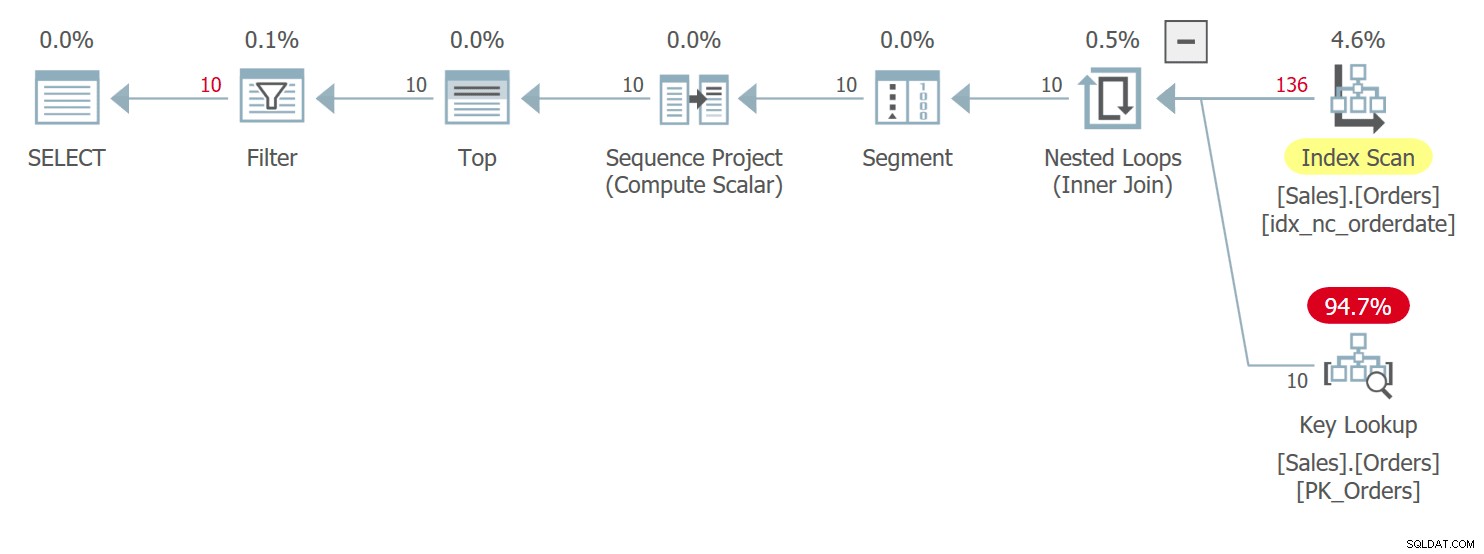
Plan dla zapytania 1 pokazano na rysunku 1.
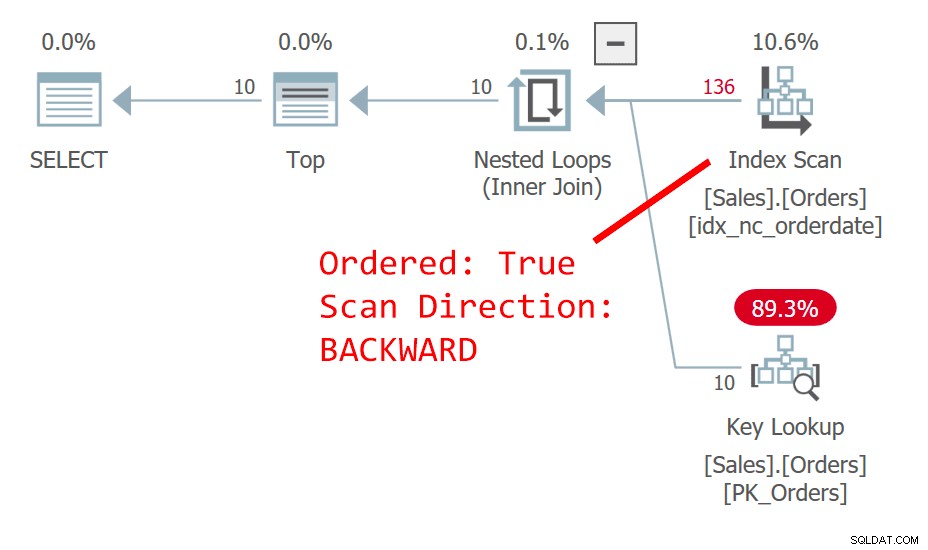 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Zapytanie porządkuje wiersze według daty zamówienia malejąco. Kolumna data zamówienia nie identyfikuje jednoznacznie wiersza. Ta niedeterministyczna kolejność oznacza, że koncepcyjnie nie ma preferencji między wierszami z tą samą datą. W przypadku powiązań to, który wiersz będzie preferowany przez program SQL Server, to takie elementy, jak wybór planu i fizyczny układ danych — a nie coś, na czym można polegać jako na powtarzalności. Plan na rysunku 1 skanuje indeks według daty zamówienia uporządkowanej wstecz. Zdarza się, że ta tabela ma indeks klastrowy o identyfikatorze zamówienia, a w tabeli klastrowej klucz indeksu klastrowego jest używany jako lokalizator wierszy w indeksach nieklastrowanych. W rzeczywistości jest niejawnie pozycjonowany jako ostatni kluczowy element we wszystkich indeksach nieklastrowanych, mimo że teoretycznie SQL Server mógł umieścić go w indeksie jako dołączoną kolumnę. Tak więc, domyślnie, indeks nieklastrowany w dniu zamówienia jest faktycznie zdefiniowany w dniu (data zamówienia, id zamówienia). W konsekwencji, w naszym uporządkowanym wstecznym skanowaniu indeksu, między powiązanymi wierszami na podstawie daty zamówienia, dostęp do wiersza o wyższej wartości orderid jest uzyskiwany przed wierszem o niższej wartości orderid. To zapytanie generuje następujące dane wyjściowe:
id zamówienia datazamówienia klienta ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 04.05.2019 62
Następnie użyj następującego zapytania (nazwij je Zapytanie 2), aby uzyskać drugą stronę z 10 wierszami:
SELECT identyfikator zamówienia, data zamówienia, custid FROM Sales. Zamówienia ORDER BY data zamówienia DESC OFFSET 10 ROWS FETCH FETCH NEXT 10 ROWS ONLY;
Plan dla zapytania pokazano na rysunku 2.
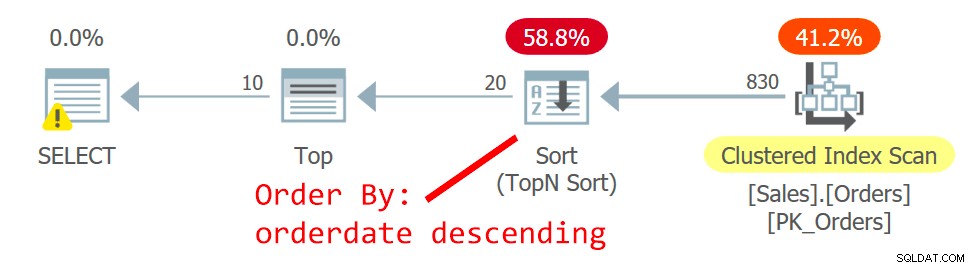
Rysunek 2:Plan dla zapytania 2
Optymalizator wybiera inny plan — jeden zeskanuje indeks klastrowy w sposób nieuporządkowany i używa sortowania TopN do obsługi żądania operatora Top w celu obsługi filtra pobierania z przesunięciem. Powodem tej zmiany jest to, że plan na rysunku 1 używa nieklastrowanego indeksu nieobejmującego, a im dalej strona jest poszukiwana, tym więcej jest wymaganych wyszukiwań. Z żądaniem drugiej strony przekroczyłeś punkt krytyczny, który uzasadnia użycie indeksu nieobejmującego.
Mimo że skanowanie indeksu klastrowego, który jest zdefiniowany z identyfikatorem zamówienia jako kluczem, jest skanowaniem nieuporządkowanym, aparat pamięci masowej stosuje wewnętrzne skanowanie kolejności indeksów. Ma to związek z rozmiarem indeksu. Do 64 stron aparat pamięci masowej generalnie preferuje skanowanie w kolejności indeksu niż skanowanie w kolejności alokacji. Nawet jeśli indeks był większy, w ramach poziomu izolacji zatwierdzonego odczytu i danych, które nie są oznaczone jako tylko do odczytu, aparat magazynu używa skanowania kolejności indeksów, aby uniknąć podwójnego czytania i pomijania wierszy w wyniku podziałów stron, które występują podczas skanowanie. W danych warunkach, w praktyce, pomiędzy wierszami z tą samą datą, ten plan uzyskuje dostęp do wiersza o niższym identyfikatorze zamówienia przed wierszem o wyższym identyfikatorze zamówienia.
To zapytanie generuje następujące dane wyjściowe:
id zamówienia datazamówienia klienta ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019- 29.04.53 11058 29.04.2019 6
Zauważ, że nawet jeśli podstawowe dane się nie zmieniły, to w rezultacie to samo zamówienie (o identyfikatorze zamówienia 11069) zostało zwrócone zarówno na pierwszej, jak i drugiej stronie!
Mamy nadzieję, że najlepsza praktyka jest tutaj jasna. Dodaj rozstrzygający remis do swojego zamówienia według listy, aby uzyskać deterministyczny porządek. Na przykład porządek według daty zamówienia malejąco, identyfikator zamówienia malejąco.
Spróbuj ponownie zapytać o pierwszą stronę, tym razem w porządku deterministycznym:
SELECT identyfikatorzamOtrzymujesz następujące dane wyjściowe, gwarantowane:
id zamówienia datazamówienia klienta ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 04.05.2019 62Zapytaj o drugą stronę:
SELECT identyfikatorzamOtrzymujesz następujące dane wyjściowe, gwarantowane:
id zamówienia datazamówienia klienta ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 29.04.2019 6Dopóki nie nastąpiły żadne zmiany w danych bazowych, masz gwarancję, że otrzymasz kolejne strony bez powtórzeń lub przeskakiwania wierszy między stronami.
W podobny sposób, używając funkcji okna, takich jak ROW_NUMBER w niedeterministycznej kolejności, można uzyskać różne wyniki dla tego samego zapytania w zależności od kształtu planu i rzeczywistej kolejności dostępu między powiązaniami. Rozważ następujące zapytanie (nazwij je Zapytanie 3), implementujące żądanie pierwszej strony przy użyciu numerów wierszy (wymuszając użycie indeksu daty zamówienia w celach ilustracyjnych):
WITH C AS ( SELECT identyfikator zamówienia, data zamówienia, custid, ROW_NUMBER() OVER(ORDER BY datazam I 10;Plan dla tego zapytania pokazano na rysunku 3:
Rysunek 3:Plan dla zapytania 3Masz tutaj bardzo podobne warunki do tych, które opisałem wcześniej dla Zapytania 1 z jego planem, który został pokazany wcześniej na Rysunku 1. Pomiędzy wierszami z powiązaniami w wartościach orderdate, ten plan uzyskuje dostęp do wiersza z wyższą wartością orderid przed wierszem z niższym wartość identyfikatora zamówienia. To zapytanie generuje następujące dane wyjściowe:
identyfikator zamówienia data zamówienia klienta ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 04.05.2019 62Następnie ponownie uruchom zapytanie (nazwijmy je Query 4), żądając pierwszej strony, tylko tym razem wymuś użycie indeksu klastrowego PK_Orders:
WITH C AS ( SELECT identyfikator zamówienia, data zamówienia, custid, ROW_NUMBER() OVER(ORDER BY data zamówienia DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT identyfikator zamówienia, data zamówienia, custid FROM C WHERE n BETWEEN 1 I 10;Plan dla tego zapytania pokazano na rysunku 4.
Rysunek 4:Plan dla zapytania 4Tym razem masz bardzo podobne warunki do tych, które opisałem wcześniej dla zapytania 2 z jego planem, który pokazano wcześniej na rysunku 2. Pomiędzy wierszami z powiązaniami w wartościach orderdate ten plan uzyskuje dostęp do wiersza z niższą wartością orderid przed wierszem z wyższa wartość orderid. To zapytanie generuje następujące dane wyjściowe:
id zamówienia datazamówienia klienta ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 04.05.2019 62Zauważ, że te dwa wykonania dały różne wyniki, mimo że nic się nie zmieniło w podstawowych danych.
Ponownie, najlepsza praktyka tutaj jest prosta — użyj kolejności deterministycznej, dodając rozstrzyganie remisów, na przykład:
WITH C AS ( SELECT id zamówienia, datazam /pre>To zapytanie generuje następujące dane wyjściowe:
id zamówienia datazamówienia klienta ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 04.05.2019 62Zwrócony zestaw gwarantuje powtarzalność niezależnie od kształtu planu.
Prawdopodobnie warto wspomnieć, że ponieważ to zapytanie nie ma kolejności prezentacji według klauzuli w zapytaniu zewnętrznym, nie ma tutaj gwarantowanej kolejności prezentacji. Jeśli potrzebujesz takiej gwarancji, musisz dodać kolejność prezentacji według klauzuli, na przykład:
WITH C AS ( SELECT identyfikator zamówienia, data zamówienia, custid, ROW_NUMBER() OVER(ORDER BY datazam n;Funkcje niedeterministyczne
Funkcja niedeterministyczna to funkcja, która przy tych samych danych wejściowych może zwracać różne wyniki w różnych wykonaniach funkcji. Klasycznymi przykładami są SYSDATETIME, NEWID i RAND (po wywołaniu bez inicjatora wejściowego). Zachowanie niedeterministycznych funkcji w T-SQL może być dla niektórych zaskakujące, aw niektórych przypadkach może powodować błędy i pułapki.
Wiele osób zakłada, że gdy wywołujesz funkcję niedeterministyczną jako część zapytania, funkcja jest oceniana osobno dla każdego wiersza. W praktyce większość funkcji niedeterministycznych jest oceniana raz na odwołanie w zapytaniu. Rozważ następujące zapytanie jako przykład:
SELECT identyfikator zamówienia, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;Ponieważ w zapytaniu istnieje tylko jedno odwołanie do każdej niedeterministycznej funkcji SYSDATETIME i RAND, każda z tych funkcji jest oceniana tylko raz, a jej wynik jest powtarzany we wszystkich wierszach wyników. Podczas uruchamiania tego zapytania otrzymałem następujące dane wyjściowe:
id zamówienia dt rnd ----------- ---------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229200746177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464...Jako przykład, w którym niezrozumienie tego zachowania może spowodować błąd, załóżmy, że musisz napisać zapytanie, które zwróci trzy losowe zamówienia z tabeli Sales.Orders. Częstą początkową próbą jest użycie zapytania TOP z porządkowaniem opartym na funkcji RAND, myśląc, że funkcja zostanie oceniona osobno dla każdego wiersza, na przykład:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();W praktyce funkcja jest oceniana tylko raz dla całego zapytania; dlatego wszystkie wiersze uzyskują ten sam wynik, a kolejność jest całkowicie nienaruszona. W rzeczywistości, jeśli sprawdzisz plan dla tego zapytania, nie zobaczysz operatora sortowania. Po kilkukrotnym uruchomieniu tego zapytania otrzymywałem ten sam wynik:
id zamówienia ----------- 11008 11019 11039Zapytanie jest w rzeczywistości równoważne z zapytaniem bez klauzuli ORDER BY, w przypadku której kolejność prezentacji nie jest gwarantowana. Tak więc technicznie kolejność jest niedeterministyczna i teoretycznie różne wykonania mogą skutkować inną kolejnością, a co za tym idzie innym wyborem 3 górnych rzędów. Jednak prawdopodobieństwo tego jest niskie i nie można myśleć o tym rozwiązaniu jako wytwarzaniu trzech losowych wierszy w każdym wykonaniu.
Wyjątkiem od reguły, że funkcja niedeterministyczna jest wywoływana raz na odwołanie w zapytaniu, jest funkcja NEWID, która zwraca globalnie unikalny identyfikator (GUID). W przypadku użycia w zapytaniu ta funkcja jest wywoływane osobno w każdym wierszu. Pokazuje to następujące zapytanie:
SELECT identyfikator zamówienia, NEWID() AS mynewid FROM Sales.Orders;To zapytanie wygenerowało następujące dane wyjściowe:
id zamówienia mynewid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98E957E81C1108 -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059-ABB17-4DFB013. -564E1257F93E...Sama wartość NEWID jest dość przypadkowa. Jeśli zastosujesz do tego funkcję SUMA KONTROLNA, otrzymasz wynik całkowity z jeszcze lepszym rozkładem losowym. Tak więc jednym ze sposobów na uzyskanie trzech losowych zamówień jest użycie zapytania TOP z porządkowaniem opartym na CHECKSUM(NEWID()), na przykład:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());Uruchom to zapytanie wielokrotnie i zwróć uwagę, że za każdym razem otrzymujesz inny zestaw trzech losowych zamówień. W jednym wykonaniu otrzymałem następujące dane wyjściowe:
id zamówienia ----------- 11031 10330 10962Oraz następujące dane wyjściowe w innym wykonaniu:
id zamówienia ----------- 10308 10885 10444Poza NEWID, co zrobić, jeśli musisz użyć w zapytaniu funkcji niedeterministycznej, takiej jak SYSDATETIME, i musisz ją oceniać osobno dla każdego wiersza? Jednym ze sposobów osiągnięcia tego jest użycie funkcji zdefiniowanej przez użytkownika (UDF), która wywołuje funkcję niedeterministyczną, na przykład:
UTWÓRZ LUB ZMIEŃ FUNKCJĘ dbo.MySysDateTime() ZWRACA DATETIME2 NA POCZĄTEK POWRÓT SYSDATETIME(); KONIEC; IdźNastępnie wywołujesz UDF w zapytaniu w ten sposób (nazwij go Zapytanie 5):
SELECT identyfikator zamówienia, dbo.MySysDateTime() AS mydt FROM Sales.Orders;Tym razem UDF jest wykonywany na wiersz. Musisz jednak mieć świadomość, że z wykonaniem UDF w każdym wierszu wiąże się dość ostra utrata wydajności. Co więcej, wywoływanie skalarnego T-SQL UDF jest inhibitorem paralelizmu.
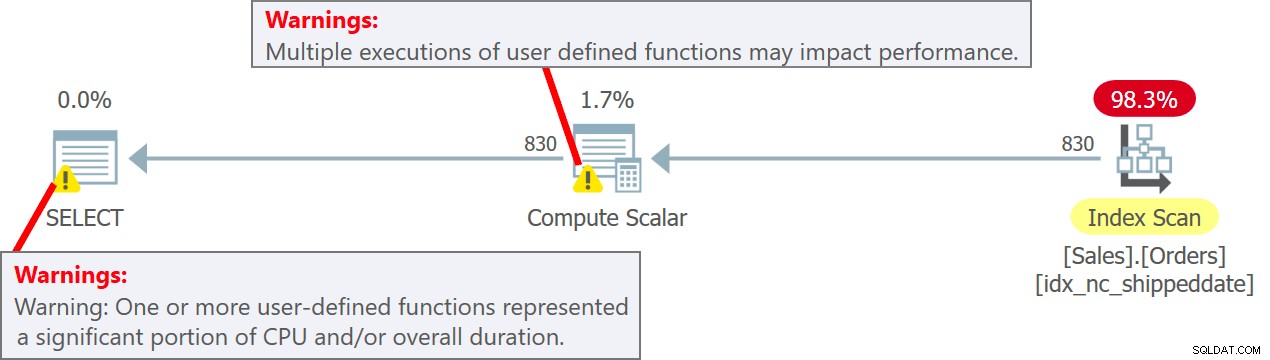
Plan dla tego zapytania pokazano na rysunku 5.
Rysunek 5:Plan dla zapytania 5Zauważ w planie, że rzeczywiście funkcja UDF jest wywoływana na wiersz źródłowy w operatorze Compute Scalar. Zauważ również, że SentryOne Plan Explorer ostrzega o potencjalnej utracie wydajności związanej z użyciem UDF zarówno w operatorze Compute Scalar, jak i w węźle głównym planu.
Otrzymałem następujące dane wyjściowe z wykonania tego zapytania:
identyfikator zamówienia mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 .. .Zauważ, że wiersze wyjściowe mają wiele różnych wartości daty i godziny w kolumnie mydt.
Być może słyszałeś, że SQL Server 2019 rozwiązuje typowy problem z wydajnością powodowany przez skalarne UDF w języku T-SQL, wprowadzając takie funkcje. Jednak UDF musi spełniać listę wymagań, aby być inline. Jednym z wymagań jest to, że funkcja UDF nie wywołuje żadnej niedeterministycznej funkcji wewnętrznej, takiej jak SYSDATETIME. Uzasadnieniem tego wymagania jest to, że być może utworzyłeś UDF dokładnie po to, aby uzyskać wykonanie na wiersz. Jeśli funkcja UDF zostanie wbudowana, podstawowa funkcja niedeterministyczna zostanie wykonana tylko raz dla całego zapytania. W rzeczywistości plan na rysunku 5 został wygenerowany w SQL Server 2019 i wyraźnie widać, że UDF nie został wbudowany. Wynika to z użycia niedeterministycznej funkcji SYSDATETIME. Możesz sprawdzić, czy UDF jest inlineable w SQL Server 2019, wysyłając zapytanie do atrybutu is_inlineable w widoku sys.sql_modules, na przykład:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID (N'dbo.MySysDateTime');Ten kod generuje następujące dane wyjściowe informujące, że UDF MySysDateTime nie jest inlineable:
is_inlineable ------------- 0Aby zademonstrować, że UDF jest inline, oto definicja UDF o nazwie EndOfyear, który akceptuje datę wejściową i zwraca odpowiednią datę końca roku:
UTWÓRZ LUB ZMIEŃ FUNKCJĘ dbo.EndOfYear(@dt AS DATE) ZWRACA DATĘ JAKO POCZĄTEK RETURN DATEADD(rok, DATEDIFF(rok, '18991231', @dt), '18991231'); KONIEC; IdźNie ma tu zastosowania niedeterministycznych funkcji, a kod spełnia również inne wymagania dotyczące wstawiania. Możesz sprawdzić, czy UDF jest inlineable, używając następującego kodu:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID (N'dbo.EndOfYear');Ten kod generuje następujące dane wyjściowe:
is_inlineable ------------- 1Następujące zapytanie (nazwij je Zapytanie 6) używa UDF EndOfYear do filtrowania zamówień, które zostały złożone na koniec roku:
SELECT identyfikator zamówienia FROM Sales.Orders WHERE datazamowienia =dbo.EndOfYear(data zamówienia);Plan dla tego zapytania pokazano na rysunku 6.
Rysunek 6:Plan dla zapytania 6Plan wyraźnie pokazuje, że UDF został wbudowany.
Wyrażenia tabelaryczne, niedeterminizm i wiele odwołań
Jak wspomniano, funkcje niedeterministyczne, takie jak SYSDATETIME, są wywoływane raz na odwołanie w zapytaniu. Ale co się stanie, jeśli raz odniesiesz się do takiej funkcji w zapytaniu w wyrażeniu tabelowym, takim jak CTE, a następnie pojawi się zapytanie zewnętrzne z wieloma odwołaniami do CTE? Wiele osób nie zdaje sobie sprawy, że każde odwołanie do wyrażenia tabeli jest rozwijane osobno, a kod wstawiany skutkuje wieloma odwołaniami do podstawowej funkcji niedeterministycznej. Dzięki funkcji takiej jak SYSDATETIME, w zależności od dokładnego czasu każdego z wykonań, możesz otrzymać inny wynik dla każdego z nich. Niektórzy uważają to zachowanie za zaskakujące.
Można to zilustrować następującym kodem:
DECLARE @i AS INT =1, @rc AS INT =NULL; GDY 1 =1 POCZĄTEK; Z C1 AS (SELECT SYSDATETIME() AS dt), C2 AS (SELECT dt FROM C1 UNION SELECT dt FROM C1) SELECT @rc =COUNT(*) FROM C2; JEŻELI @rc> 1 PRZERWA; USTAW @i +=1; KONIEC; SELECT @rc AS odrębne wartości, @i AS iteracje;Gdyby oba odwołania do C1 w zapytaniu w C2 reprezentowały to samo, ten kod spowodowałby nieskończoną pętlę. Ponieważ jednak dwa odwołania są rozwijane oddzielnie, gdy czas jest taki, że każde wywołanie odbywa się w innym interwale 100 nanosekund (dokładność wartości wyniku), suma daje w wyniku dwa wiersze, a kod powinien zerwać z pętla. Uruchom ten kod i przekonaj się sam. Rzeczywiście, po kilku iteracjach pęka. W jednej z egzekucji uzyskałem następujący wynik:
iteracje odrębnych wartości -------------- ----------- 2 448Najlepszym rozwiązaniem jest unikanie używania wyrażeń tabelowych, takich jak CTE i widoki, gdy zapytanie wewnętrzne używa obliczeń niedeterministycznych, a zapytanie zewnętrzne wielokrotnie odwołuje się do wyrażenia tabeli. Oczywiście, o ile nie rozumiesz implikacji i nie masz z nimi nic wspólnego. Alternatywnymi opcjami może być utrwalenie wewnętrznego wyniku zapytania, powiedzmy w tabeli tymczasowej, a następnie wykonanie zapytania do tabeli tymczasowej dowolną liczbę razy.
Aby zademonstrować przykłady, w których nieprzestrzeganie najlepszych praktyk może wpędzić Cię w kłopoty, załóżmy, że musisz napisać zapytanie losowo dopasowujące pracowników z tabeli HR.Employees. Do wykonania zadania pojawia się następujące zapytanie (nazwij je zapytaniem 7):
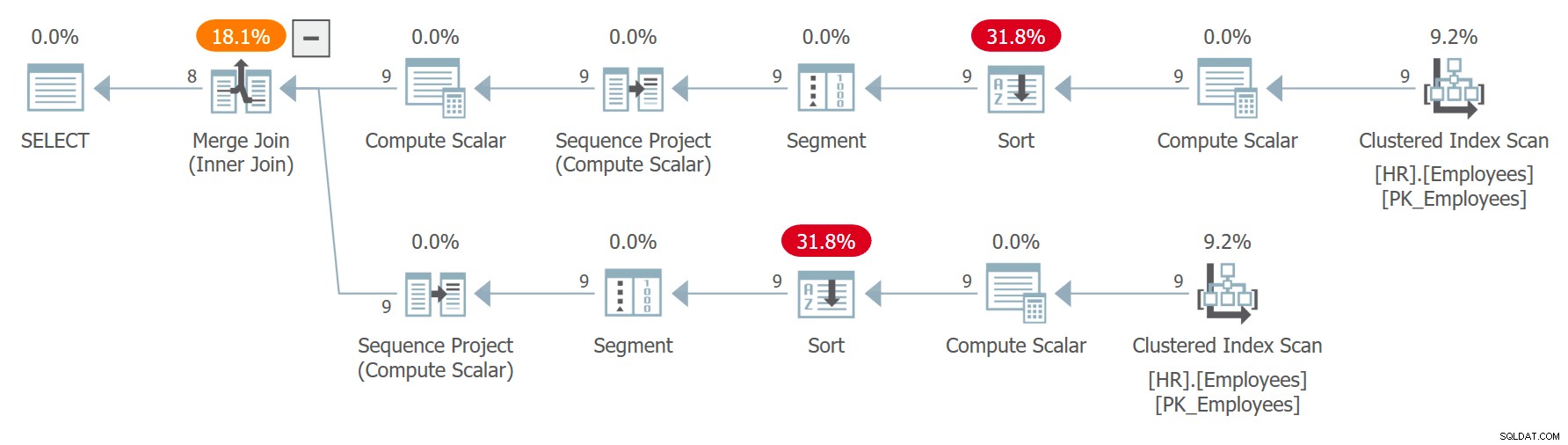
WITH C AS ( SELECT empid, imię, nazwisko, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.imię AS imię1, C1. nazwisko AS nazwisko1, C2.empid AS empid2, C2.imię AS imię2, C2.nazwisko AS nazwisko2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1;Plan dla tego zapytania pokazano na rysunku 7.
Rysunek 7:Plan dla zapytania 7Zauważ, że dwa odwołania do C są rozwijane oddzielnie, a numery wierszy są obliczane niezależnie dla każdego odwołania uporządkowanego przez niezależne wywołania wyrażenia CHECKSUM(NEWID()). Oznacza to, że nie ma gwarancji, że ten sam pracownik otrzyma ten sam numer wiersza w dwóch rozszerzonych odwołaniach. Jeśli pracownik otrzyma wiersz numer x w C1 i wiersz x – 1 w C2, zapytanie sparuje pracownika z nim samym. Na przykład w jednej z egzekucji otrzymałem następujący wynik:
empid1 imię1 nazwisko1 empid2 imię2 nazwisko2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russell King ***Zauważ, że są tu trzy przypadki par self. Łatwiej to zobaczyć, dodając filtr do zewnętrznego zapytania, który szuka konkretnie par, na przykład:
WITH C AS ( SELECT empid, imię, nazwisko, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.imię AS imię1, C1. nazwisko AS nazwisko1, C2.empid AS empid2, C2.imię AS imię2, C2.nazwisko AS nazwisko2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.empid =C2.empid;Może być konieczne kilkakrotne uruchomienie tego zapytania, aby zobaczyć problem. Oto przykład wyniku, który uzyskałem w jednej z egzekucji:
empid1 imię1 nazwisko1 empid2 imię2 nazwisko2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkZgodnie z najlepszymi praktykami, jednym ze sposobów rozwiązania tego problemu jest utrwalenie wewnętrznego wyniku zapytania w tabeli tymczasowej, a następnie wysłanie zapytania do wielu wystąpień tabeli tymczasowej w razie potrzeby.
Inny przykład ilustruje błędy, które mogą wynikać z użycia niedeterministycznej kolejności i wielu odwołań do wyrażenia tabelowego. Załóżmy, że musisz wykonać zapytanie do tabeli Sales.Orders i aby przeprowadzić analizę trendów, chcesz sparować każde zamówienie z następnym na podstawie kolejności według daty zamówienia. Twoje rozwiązanie musi być kompatybilne z systemami starszymi niż SQL Server 2012, co oznacza, że nie możesz korzystać z oczywistych funkcji LAG/LEAD. Decydujesz się na użycie CTE, które oblicza numery wierszy, aby pozycjonować wiersze na podstawie kolejności według daty zamówienia, a następnie łączysz dwie instancje CTE, parując zamówienia w oparciu o przesunięcie o 1 między numerami wierszy, tak jak w ten sposób (nazwij to zapytanie 8):
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 Z C AS C1 POŁĄCZENIE LEWE ZEWNĘTRZNE C AS C2 ON C1.n =C2.n + 1;Plan dla tego zapytania pokazano na rysunku 8.
Rysunek 8:Plan dla zapytania 8
Kolejność numerów wierszy nie jest deterministyczna, ponieważ data zamówienia nie jest unikalna. Zauważ, że dwa odniesienia do CTE są rozwijane oddzielnie. Co ciekawe, ponieważ zapytanie szuka innego podzbioru kolumn z każdej instancji, optymalizator decyduje się na użycie innego indeksu w każdym przypadku. W jednym przypadku używa uporządkowanego wstecznego skanowania indeksu według daty zamówienia, skutecznie skanując wiersze z tą samą datą na podstawie kolejności malejącej według identyfikatora zamówienia. W innym przypadku skanuje indeks klastrowy, sortuje fałsz, a następnie sortuje, ale efektywnie między wierszami z tą samą datą, uzyskuje dostęp do wierszy w kolejności rosnącej. Wynika to z podobnego rozumowania, które przedstawiłem wcześniej w części dotyczącej porządku niedeterministycznego. Może to spowodować, że ten sam wiersz otrzyma numer wiersza x w jednym wystąpieniu i wiersz o numerze x – 1 w drugim wystąpieniu. W takim przypadku złączenie skończy się dopasowaniem zamówienia do siebie zamiast do następnego, jak powinno.
Podczas wykonywania tego zapytania otrzymałem następujący wynik:
idzamowienia1 datazamowienia1 custid1 idzamowienia2 datazamowienia2 ----------- ---------- ----------- ---------- - ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05- 05 *** ...Obserwuj samodopasowania w wyniku. Ponownie problem można łatwiej zidentyfikować, dodając filtr wyszukujący samodopasowanie, na przykład:
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 Z C AS C1 LEWE ZŁĄCZE ZEWNĘTRZNE C AS C2 ON C1.n =C2.n + 1 GDZIE C1.orderid =C2.orderid;Otrzymałem następujące dane wyjściowe z tego zapytania:
idzamowienia1 datazamowienia1 custid1 idzamowienia2 datazamowienia2 ----------- ---------- ----------- ---------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 27.04.2019 34 11052 27.04.2019 11042 22.04.2019 15 11042 22.04.2019 ...Najlepszą praktyką tutaj jest upewnienie się, że używasz unikalnej kolejności, aby zagwarantować determinizm, dodając rozstrzygający, taki jak orderid, do klauzuli kolejności okien. Więc nawet jeśli masz wiele odniesień do tego samego CTE, numery wierszy będą takie same w obu. Jeśli chcesz uniknąć powtarzania obliczeń, możesz również rozważyć utrwalenie wewnętrznego wyniku zapytania, ale wtedy musisz wziąć pod uwagę dodatkowy koszt takiej pracy.
CASE/NULLIF i funkcje niedeterministyczne
Jeśli masz wiele odwołań do niedeterministycznej funkcji w zapytaniu, każde odwołanie jest oceniane osobno. To, co może być zaskakujące, a nawet skutkować błędami, to fakt, że czasami piszesz jedną referencję, ale niejawnie zostaje ona przekształcona w wiele referencji. Taka jest sytuacja przy niektórych zastosowaniach wyrażenia CASE i funkcji IIF.
Rozważ następujący przykład:
WYBIERZ PRZYPADEK ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Parzyste' WHEN 1 THEN 'Nieparzyste' KONIEC;Tutaj wynik testowanego wyrażenia jest nieujemną liczbą całkowitą, więc wyraźnie musi być parzysta lub nieparzysta. Nie może być ani parzyste, ani dziwne. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Wniosek
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!