Gdy plan wykonania zawiera skan struktury indeksu b-drzewa, silnik pamięci może móc wybrać jedną z dwóch strategii dostępu fizycznego podczas wykonywania planu:
- Przestrzegaj struktury indeksu b-drzewa; lub,
- zlokalizuj strony, korzystając z wewnętrznych informacji o alokacji stron.
Jeśli wybór jest dostępny, aparat magazynu podejmuje decyzję dotyczącą środowiska uruchomieniowego przy każdym wykonaniu. Ponowna kompilacja planu nie wymagane, aby zmienił zdanie.
Strategia b-tree zaczyna się od korzenia drzewa, schodzi do skrajnej krawędzi poziomu liścia (w zależności od tego, czy skanowanie jest prowadzone w przód czy w tył), a następnie podąża za łączami do stron na poziomie liścia, aż do osiągnięcia drugiego końca indeksu . Strategia alokacji wykorzystuje struktury Index Allocation Map (IAM) do lokalizowania stron bazy danych przydzielonych do indeksu. Każda strona uprawnień odwzorowuje alokacje na interwał 4 GB w pojedynczym fizycznym pliku bazy danych, więc skanowanie łańcuchów uprawnień powiązanych z indeksem ma tendencję do uzyskiwania dostępu do stron indeksu w fizycznej kolejności plików (przynajmniej na tyle, na ile może to stwierdzić SQL Server).
Główne różnice między tymi dwiema strategiami to:
- Skanowanie b-drzewa może dostarczyć wiersze do procesora zapytań w kolejności kluczy indeksu; skanowanie oparte na IAM nie może;
- skanowanie b-drzewa może nie być w stanie wysyłać dużych żądań wejścia/wyjścia z wyprzedzeniem, jeśli logiczne, ciągłe strony indeksu nie są również fizycznie ciągłe (np. w wyniku podziału strony w indeksie).
Skanowanie b-drzewa jest zawsze dostępne dla indeksu. Często przytaczane warunki, aby skany kolejności alokacji były dostępne, to:
- Plan zapytania musi umożliwiać nieuporządkowane skanowanie indeksu;
- indeks musi mieć co najmniej 64 strony; i
- albo
TABLOCKlubNOLOCKpodpowiedź musi być określona.
Pierwszy warunek oznacza po prostu, że optymalizator zapytań musi oznaczyć skan za pomocą Ordered:False własność. Oznaczanie skanu Ordered:False oznacza, że poprawne wyniki z planu wykonania nie wymagają skanowanie, aby zwrócić wiersze w kolejności klucza indeksu (choć może to zrobić, jeśli jest to wygodne lub w inny sposób konieczne).
Drugi warunek (rozmiar) dotyczy tylko SQL Server 2005 i nowszych. Odzwierciedla to, że wykonanie skanowania opartego na IAM wiąże się z pewnym kosztem początkowym, więc musi być minimalna liczba stron, aby potencjalne oszczędności mogły spłacić początkową inwestycję. „64 strony” odnosi się do wartości data_pages dla IN_ROW_DATA tylko jednostka alokacji, jak podano w sys.allocation_units.
Oczywiście, zysk ze skanowania zlecenia alokacji może być tylko wtedy, gdy możliwe jest rozważenie większego odczytu z wyprzedzeniem faktycznie wchodzą w grę, ale SQL Server obecnie nie uwzględnia tego czynnika. W szczególności nie uwzględnia, jaka część indeksu znajduje się obecnie w pamięci, ani nie obchodzi go, jak pofragmentowany jest indeks.
Trzeci warunek to prawdopodobnie najmniej kompletny opis na liście. Wskazówki nie są w rzeczywistości wymagane , chociaż można ich użyć do spełnienia rzeczywistych wymagań:dane muszą być gwarantowane, że się nie zmienią podczas skanowania lub (co bardziej kontrowersyjne) musimy wskazać, że nie obchodzi nas to o potencjalnie niedokładnych wynikach, wykonując skanowanie na odczytanym, niezatwierdzonym poziomie izolacji.
Nawet z tymi wyjaśnieniami, lista warunków skanowania na zlecenie alokacji wciąż nie jest kompletna. Istnieje wiele ważnych zastrzeżeń i wyjątków, do których wkrótce przejdziemy.
Demo
Następujące zapytanie korzysta z przykładowej bazy danych AdventureWorks:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Zauważ, że tabela Person zawiera 3869 stron. Plan powykonawczy (rzeczywisty) jest następujący (pokazany w Eksploratorze planów SQL Sentry):
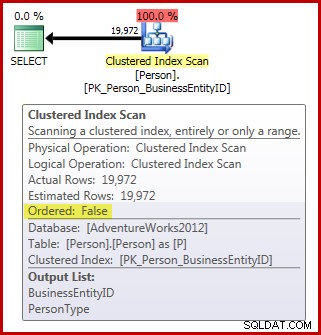
Jeśli chodzi o wymagania dotyczące skanowania kolejności alokacji, mamy do tej pory:
- Plan ma wymagany
Ordered:Falsewłasność; oraz, - tabela ma ponad 64 strony; ale,
- Nie zrobiliśmy nic, aby zapewnić, że dane nie mogą ulec zmianie podczas skanowania. Zakładając, że nasza sesja używa domyślnego zatwierdzonego odczytu poziom izolacji, skanowanie nie jest wykonywane przy odczycie niezatwierdzonym poziom izolacji.
W konsekwencji spodziewalibyśmy się, że ten skan będzie wykonywany przez skanowanie b-drzewa, a nie przez IAM. Wyniki zapytania wskazują, że to prawdopodobnie prawda:
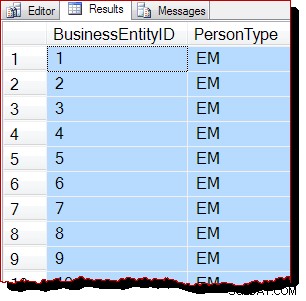
Wiersze są zwracane w kolejności klucza Clustered Index (według BusinessEntityID ). Powinienem wyraźnie stwierdzić, że ta kolejność wyników absolutnie nie jest gwarantowana i nie należy na nich polegać. Zamówione wyniki są gwarantowane tylko przez odpowiedni ORDER BY najwyższego poziomu klauzula.
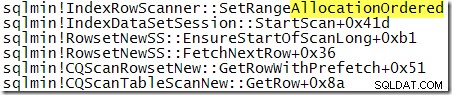
Niemniej jednak obserwowana kolejność wyników jest poszlakowym dowodem na to, że skanowanie zostało wykonane tym razem zgodnie ze strukturą b-drzewa indeksu klastrowego. Jeśli potrzeba więcej dowodów, możemy dołączyć debugger i spojrzeć na ścieżkę kodu wykonywaną przez SQL Server podczas skanowania:

Stos wywołań wyraźnie pokazuje skan za b-drzewo.
Dodawanie wskazówki dotyczącej blokady tabeli
Teraz modyfikujemy zapytanie, aby zawierało wskazówkę dotyczącą blokady tabeli:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); Przy domyślnym poziomie izolacji odczytu zatwierdzonego blokowania blokada na poziomie tabeli udostępnionej zapobiega wszelkim możliwym współbieżnym modyfikacjom danych. Po spełnieniu wszystkich trzech warunków wstępnych dla skanowań opartych na uprawnieniach można oczekiwać, że SQL Server będzie używał skanowania w kolejności alokacji. Plan wykonania jest taki sam jak poprzednio, więc nie będę tego powtarzał, ale wyniki zapytania na pewno wyglądają inaczej:
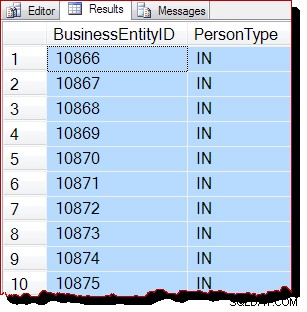
Wyniki są nadal najwyraźniej uporządkowane według BusinessEntityID , ale punkt wyjścia (10866) jest inny. Rzeczywiście, jeśli przewiniemy wyniki, wkrótce natkniemy się na sekcje, które są w bardziej oczywisty sposób niewłaściwie uporządkowane:
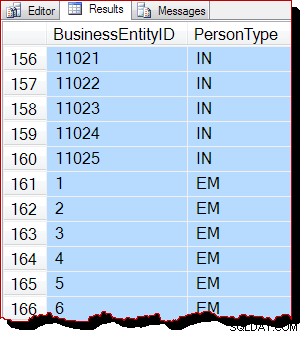
Porządkowanie częściowe jest spowodowane skanowaniem kolejności alokacji, które przetwarza jednocześnie całą stronę indeksu. Wyniki na stronie zdarza się, że są zwracane uporządkowane według klucza indeksu, ale kolejność zeskanowanych stron jest teraz inna. Ponownie, powinienem podkreślić, że wyniki mogą wyglądać inaczej:nie ma gwarancji kolejności wyników, nawet w obrębie strony, bez najwyższego poziomu ORDER BY w pierwotnym zapytaniu.
Dla porównania ze stosem wywołań pokazanym wcześniej, jest to ślad stosu uzyskany, gdy SQL Server przetwarzał zapytanie za pomocą TABLOCK wskazówka:
Przejście trochę dalej przez wykonanie:

Oczywiście SQL Server wykonuje skanowanie według kolejności alokacji, gdy określono blokadę tabeli. Szkoda, że w planie powykonawczym nie ma wskazania, jaki rodzaj skanowania został użyty w czasie wykonywania. Przypominamy, że typ skanowania jest wybierany przez silnik pamięci masowej i może zmieniać się między wykonaniami bez ponownej kompilacji planu.
Inne sposoby spełnienia trzeciego warunku
Powiedziałem wcześniej, że aby uzyskać skanowanie oparte na uprawnieniach, musimy upewnić się, że dane nie mogą ulec zmianie pod skanowaniem, gdy jest w toku, lub musimy uruchomić zapytanie na poziomie izolacji odczytu niezatwierdzonego. Widzieliśmy, że wskazówka blokady tabeli przy blokowaniu zatwierdzonej izolacji odczytu jest wystarczająca do spełnienia pierwszego z tych wymagań i łatwo jest wykazać, że przy użyciu NOLOCK/READUNCOMMITTED wskazówka umożliwia również skanowanie kolejności alokacji za pomocą zapytania demonstracyjnego.
W rzeczywistości istnieje wiele sposobów spełnienia trzeciego warunku, w tym:
- Zmienianie indeksu, aby zezwalać tylko na blokady tabeli;
- uczynienie bazy danych tylko do odczytu (więc dane nie ulegną zmianie); lub,
- zmiana sesji poziom izolacji do
READ UNCOMMITTED.
Istnieje jednak o wiele ciekawsze wariacje na ten temat, co oznacza, że musimy zmienić trzy warunki określone wcześniej…
Poziomy izolacji wersjonowania wierszy
Włącz izolację odczytu zatwierdzonej migawki (RCSI) w bazie danych AdventureWorks i uruchom test z TABLOCK wskazówka ponownie (przy odczycie popełnionej izolacji):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Przy aktywnym RCSI, uporządkowany według indeksu skanowanie jest używane z TABLOCK , a nie skan kolejności alokacji, który widzieliśmy tuż wcześniej. Powodem jest TABLOCK wskazówka określa blokadę współdzieloną na poziomie tabeli, ale przy włączonym RCSI brak blokad współdzielonych są brane. Bez blokady wspólnej tabeli nie spełniliśmy wymogu zapobiegania równoczesnym modyfikacjom danych w trakcie skanowania, więc nie można użyć skanowania uporządkowanego według alokacji.
Możliwe jest jednak uzyskanie skanowania uporządkowanego według alokacji, gdy włączone jest RCSI. Jednym ze sposobów jest użycie TABLOCKX wskazówka (dla wyłączności na poziomie tabeli) lock) zamiast TABLOCK . Moglibyśmy również zachować TABLOCK podpowiedź i dodaj kolejną, np. READCOMMITTEDLOCK lub REPEATABLE READ lub SERIALIZABLE … i tak dalej. Wszystko to działa, zapobiegając możliwości równoczesnych modyfikacji poprzez blokowanie wspólnej tabeli, kosztem utraty korzyści wynikających z RCSI . Nadal możemy również uzyskać skanowanie kolejności alokacji za pomocą NOLOCK lub READUNCOMMITTED oczywiście wskazówka.
Sytuacja w przypadku izolacji migawki (SI) jest bardzo podobna do RCSI i nie została szczegółowo zbadana ze względu na brak miejsca.
TABLESAMPLE zawsze* wykonuje skanowanie kolejności alokacji
TABLESAMPLE klauzula jest interesującym wyjątkiem od wielu rzeczy, które omówiliśmy do tej pory.
Określanie TABLESAMPLE klauzula zawsze* powoduje skanowanie kolejności alokacji, nawet w przypadku RCSI lub SI, a nawet bez podpowiedzi. Aby było jasne, skan kolejności alokacji wynikający z użycia TABLESAMPLE zachowuje semantykę RCSI/SI – skanowanie wykorzystuje wersje wierszy, a odczyt nie blokuje zapisu (i odwrotnie).
Drugą niespodzianką jest to, że TABLESAMPLE zawsze* wykonuje skanowanie na podstawie uprawnień, nawet jeśli tabela ma mniej niż 64 strony . Ma to sens, ponieważ dokumentacja przynajmniej wskazuje, że SYSTEM metoda próbkowania wykorzystuje strukturę IAM (więc nie ma innego wyjścia, jak wykonać skanowanie kolejności alokacji):
SYSTEM Jest metodą próbkowania zależną od wdrożenia, określoną przez normy ISO. W SQL Server jest to jedyna dostępna metoda próbkowania i jest stosowana domyślnie. SYSTEM stosuje metodę próbkowania opartą na stronach, w której losowy zestaw stron z tabeli jest wybierany do próbki, a wszystkie wiersze na tych stronach są zwracane jako podzbiór próbki.
* Wyjątek występuje, gdy ROWS lub PERCENT specyfikacja w TABLESAMPLE klauzula oznacza 100% tabeli. Określanie większej liczby ROWS niż wskazują metadane, które znajdują się obecnie w tabeli, również nie będą działać. Korzystanie z TABLESAMPLE SYSTEM (100 PERCENT) lub odpowiednik nie wymuś skanowanie kolejności alokacji.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Wyniki:
Efekt TOP i SET ROWCOUNT
Krótko mówiąc, żadna z tych opcji nie ma wpływu na decyzję o użyciu skanowania kolejności alokacji, czy nie. Może to wydawać się zaskakujące w przypadkach, gdy „oczywiste” jest, że zeskanowanych zostanie mniej niż 64 strony.
Na przykład poniższe zapytania używają skanowania opartego na uprawnieniach do zwrócenia 5 wierszy ze skanowania:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; Wyniki są takie same dla obu:
Oznacza to, że TOP i SET ROWCOUNT zapytania mogą ponieść koszty konfiguracji skanowania w kolejności alokacji, nawet jeśli zeskanowanych zostanie mniej niż 64 strony. W ramach łagodzenia, bardziej złożone zapytania TOP z selektywnymi predykatami wepchniętymi do skanowania mogą nadal korzystać ze skanowania w kolejności alokacji. Jeśli skanowanie musi przetworzyć 10 000 stron, aby znaleźć pierwsze 5 pasujących wierszy, skanowanie kolejności alokacji może nadal być wygrane.
Zapobieganie wszystkim* skanom kolejności alokacji w całej instancji
Nie jest to coś, co prawdopodobnie zrobisz celowo, ale istnieje ustawienie serwera, które uniemożliwi skanowanie według kolejności alokacji dla wszystkich* zapytań użytkowników we wszystkich bazach danych.
Choć może się to wydawać mało prawdopodobne, omawiane ustawienie to opcja konfiguracji serwera progu kursora, która ma następujący opis w Books Online:
Opcja próg kursora określa liczbę wierszy w zestawie kursorów, przy których zestawy kluczy kursora są generowane asynchronicznie. Gdy kursory generują zestaw kluczy dla zestawu wyników, optymalizator zapytań szacuje liczbę wierszy, które zostaną zwrócone dla tego zestawu wyników. Jeśli optymalizator zapytań oszacuje, że liczba zwróconych wierszy jest większa niż ten próg, kursor jest generowany asynchronicznie, umożliwiając użytkownikowi pobranie wierszy z kursora, podczas gdy kursor jest nadal zapełniany. W przeciwnym razie kursor jest generowany synchronicznie, a zapytanie czeka, aż wszystkie wiersze zostaną zwrócone.
Jeśli cursor threshold opcja jest ustawiona na dowolną inną niż –1 (domyślnie), żadne skanowanie w kolejności alokacji nie będzie wykonywane dla zapytań użytkowników w żadnej bazie danych w instancji SQL Server.
Innymi słowy, jeśli asynchroniczne zapełnianie kursorów jest włączone, żadne skanowanie oparte na uprawnieniach nie jest dla Ciebie.
* Wyjątkiem jest (nie 100%) TABLESAMPLE zapytania. Zapytania wewnętrzne generowane przez system w celu tworzenia statystyk i aktualizacji statystyk również nadal używają skanów uporządkowanych według alokacji.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Wyniki (bez skanowania kolejności alokacji):
Można się tylko domyślać, że asynchroniczna populacja kursorów z jakiegoś powodu nie działa dobrze ze skanowaniem według kolejności alokacji. Całkowicie nieoczekiwane jest, że to ograniczenie wpłynie na wszystkie zapytania użytkowników bez kursora jak dobrze. Być może SQL Server jest zbyt trudny do wykrycia, czy zapytanie jest uruchomione jako część zewnętrznie wydanego kursora API? Kto wie.
Byłoby miło, gdyby ten efekt uboczny został gdzieś oficjalnie udokumentowany, choć w Books Online trudno dokładnie określić, dokąd powinien zmierzać. Zastanawiam się, ile systemów produkcyjnych nie używa z tego powodu skanowania kolejności alokacji? Może nie wiele, ale nigdy nie wiadomo.
Podsumowując, oto podsumowanie. Skanowanie według alokacji jest dostępne, jeśli:
- Opcja serwera
cursor thresholdjest ustawiony na –1 (domyślnie); i, - operator skanowania planu zapytania ma
Ordered:Falsewłasność; i, - całkowita liczba stron_danych z
IN_ROW_DATAjednostek alokacji wynosi co najmniej 64; i, - albo:
- SQL Server ma akceptowalną gwarancję, że współbieżne modyfikacje są niemożliwe; lub
- skanowanie działa na poziomie izolacji odczytu niezatwierdzonych.
Niezależnie od powyższego, skan z TABLESAMPLE klauzula zawsze używa skanów uporządkowanych według alokacji (z jednym wyjątkiem technicznym odnotowanym w głównym tekście).



