Planowanie pojemności z wykorzystaniem danych dotyczących wydajności
Szacowana liczba wierszy do odczytania
Kompresja i jej wpływ na wydajność
Niespodzianki dotyczące wydajności i założenia:GROUP BY vs. DISTINCT
Jednym ze sposobów na uzyskanie indeksu wyszukiwania wiodącego %wildcard
Kontynuacja nr 1 w przypadku wiodących poszukiwań dzikich kart
Minimalizowanie wpływu poszerzenia kolumny TOŻSAMOŚĆ – część 4
Rozszerzenie zastosowań DBCC CLONEDATABASE
Dopasowywanie wzorów:więcej zabawy, gdy byłem dzieckiem
Webinarium Plan Explorer 3.0 — próbki i pytania i odpowiedzi
Sort, który rozlewa się do poziomu 15 000
SQL Sentry to teraz SentryOne
Wdrażanie niestandardowego sortowania
Migracja baz danych do Azure SQL Database
Czy komentarze mogą utrudniać działanie procedury składowanej?
Trendy w zakresie sprzętu i infrastruktury baz danych
Czy wyszukiwanie RID jest szybsze niż wyszukiwanie klucza?
Wewnętrzne elementy Z SZYFROWANIEM
Ulepszona obsługa równoległych przebudów statystyk
Liczba odczytanych wierszy / Rzeczywiste ostrzeżenia o odczytaniu wierszy w Eksploratorze planów

Konfiguracja poczty bazy danych w SQL Server
Sqlserver
Jak korzystać z funkcji analitycznych w Oracle (nad partycją według słowa kluczowego)
Oracle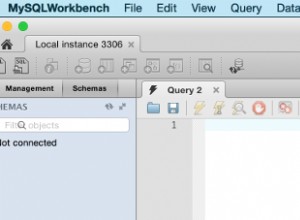
Jak zatrzymać/uruchomić MySQL za pomocą MySQL Workbench
Mysql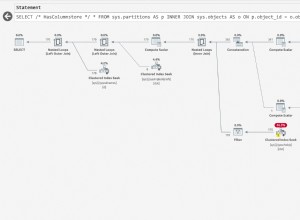
Wydajność partycji sys.
Database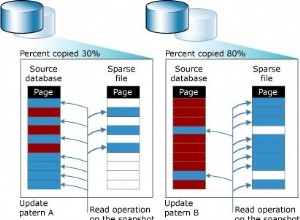
Migawki bazy danych programu SQL Server -4
Sqlserver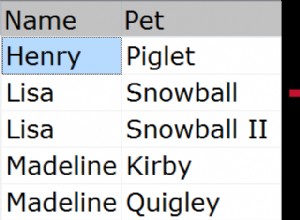
Zgrupowana konkatenacja w SQL Server
Sqlserver